the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 13 Mar 2019
| 13 Mar 2019
A multi-collocation method for coastal zone observations with applications to Sentinel-3A altimeter wave height data
Johannes Schulz-Stellenfleth
Joanna Staneva
In many coastal areas there is an increasing number and variety of observation data available, which are often very heterogeneous in their temporal and spatial sampling characteristics. With the advent of new systems, like the radar altimeter on board the Sentinel-3A satellite, a lot of questions arise concerning the accuracy and added value of different instruments and numerical models. Quantification of errors is a key factor for applications, like data assimilation and forecast improvement. In the past, the triple collocation method to estimate systematic and stochastic errors of measurements and numerical models was successfully applied to different data sets. This method relies on the assumption that three independent data sets provide estimates of the same quantity. In coastal areas with strong gradients even small distances between measurements can lead to larger differences and this assumption can become critical. In this study the triple collocation method is extended in different ways with the specific problems of the coast in mind. In addition to nearest-neighbour approximations considered so far, the presented method allows for use of a large variety of interpolation approaches to take spatial variations in the observed area into account. Observation and numerical model errors can therefore be estimated, even if the distance between the different data sources is too large to assume that they measure the same quantity. If the number of observations is sufficient, the method can also be used to estimate error correlations between certain data source components. As a second novelty, an estimator for the uncertainty in the derived observation errors is derived as a function of the covariance matrices of the input data and the number of available samples.
In the first step, the method is assessed using synthetic observations and Monte Carlo simulations. The technique is then applied to a data set of Sentinel-3A altimeter measurements, in situ wave observations, and numerical wave model data with a focus on the North Sea. Stochastic observation errors for the significant wave height, as well as bias and calibration errors, are derived for the model and the altimeter. The analysis indicates a slight overestimation of altimeter wave heights, which become more pronounced at higher sea states. The smallest stochastic errors are found for the in situ measurements.
Different observation geometries of in situ data and altimeter tracks are furthermore analysed, considering 1-D and 2-D interpolation approaches. For example, the geometry of an altimeter track passing between two in situ wave instruments is considered with model data being available at the in situ locations. It is shown that for a sufficiently large sample, the errors of all data sources, as well as the error correlations of the model, can be estimated with the new method.
- Article
(3549 KB) - Full-text XML
- BibTeX
- EndNote





Coastal areas like the German Bight are often characterised by strongly heterogeneous ocean dynamics, typically associated with complicated bathymetry, small-scale coastline features, and river runoff. A few instruments, like high-frequency (HF) radar, are able to capture at least 2-D surface currents with large coverage and high resolution quite nicely. Such systems have a typical range of about 100 km, spatial resolutions on the kilometre scale, and about 20 min sampling (Stanev et al., 2015). However, most instruments provide only point measurements (e.g. buoys) or transects (e.g. satellite altimeter). The combination, and interpretation, of such data is therefore often a challenge. In heterogeneous coastal areas with strong gradients, spatially distributed instruments can observe very different components of the dynamics, even if they are in close proximity.
In the following, this situation is studied in more detail with respect to ocean waves and the significant wave height in particular. Wave height information is of paramount importance for many applications, e.g. shipping, offshore operations, or coastal protection. Although numerical wave forecast models have reached an impressive level of accuracy, there is still room for improvement, in particular in coastal areas with complicated dissipation processes associated with wave breaking and bed friction (Woolf et al., 2002; Reistad et al., 2011; Voorrips et al., 1997; Herbers et al., 2000; Bouws and Komen, 1983; Young et al., 2013; Semedo et al., 2015), as well as with coupling processes between ocean waves, ocean circulation, and the atmosphere (Cavaleri et al., 2018; Staneva et al., 2017; Alari et al., 2016). The focus in this study is on the North Sea, which has interesting ocean wave dynamics mainly caused by the semi-enclosed geometry (Semedo et al., 2015; Voorrips et al., 1997; Boukhanovsky et al., 2007; Staneva et al., 2014). The bathymetry of the considered area with the locations of some in situ wave measurement stations used in the following analysis is shown in Fig. 1.
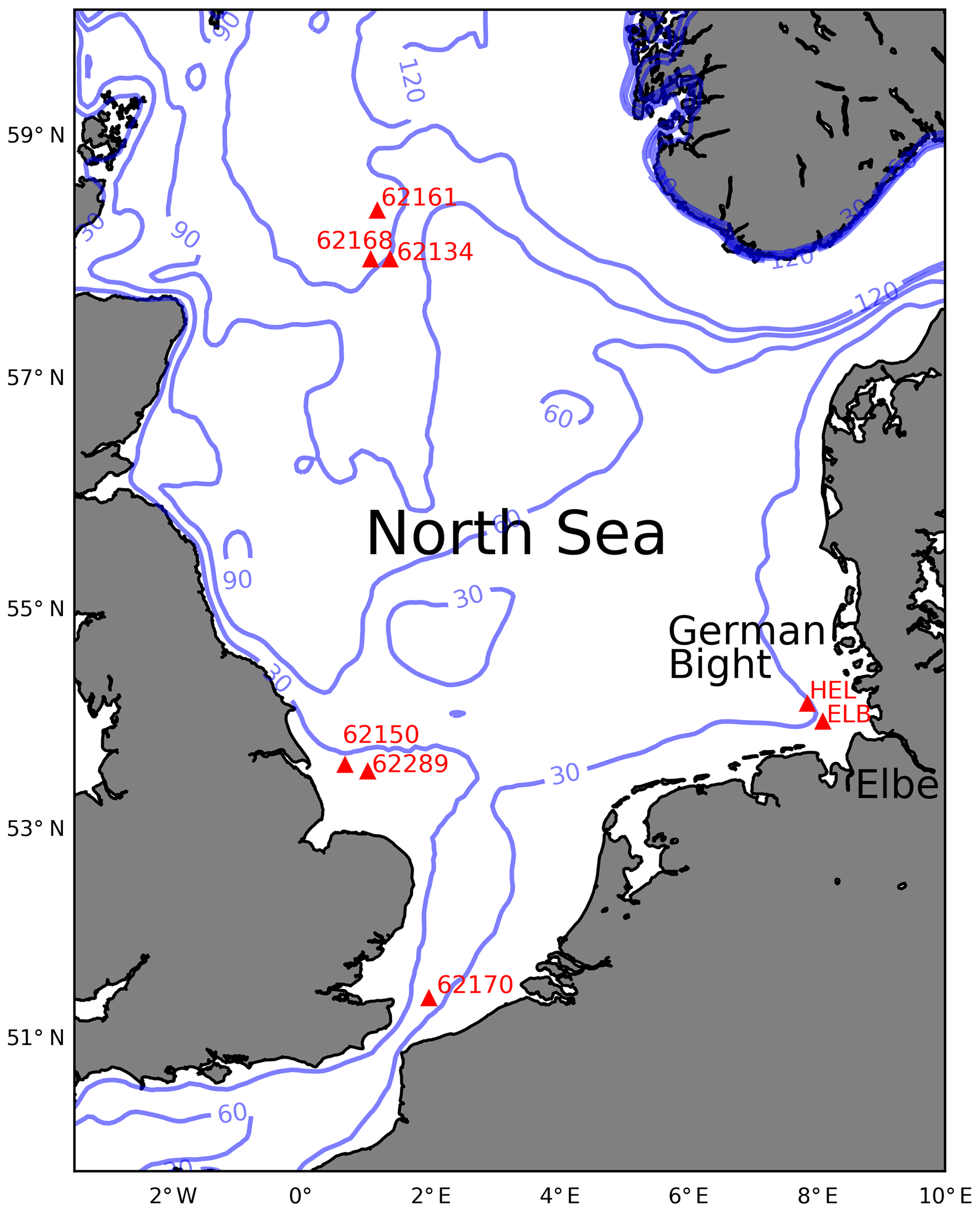
Figure 1Bathymetry of the North Sea with the locations of some in situ wave observation instruments considered in this study. The plot shows isobaths for 30, 60, 90, and 120 m water depth.
Traditionally, validations of new data sets are performed by comparing to data from established standard in situ measurements, which are regarded as a reference. As a first step this is acceptable; however, one has to take into account that these reference instruments are affected by measurement errors as well, and the separation of the error contributions from the new data set and the reference instrument is, in general, not possible unless additional information is used. This is easy to see if two data sets, x and y, with uncorrelated additive noise are considered, i.e.
where t represents the “truth”. If statistics are performed on the difference ξ of x and y, one gets for the mean square error
and it is apparent that it is not possible to derive either or from ξ alone. The usual approach is therefore to use additional data sets and to make certain a priori assumptions about the errors. If only one data set is added, this leads to the triple collocation method, which has been used and discussed in a number of previous studies (Janssen et al., 2007; Vogelzang and Stoffelen, 2012; Stoffelen, 1998; Caires and Sterl, 2003; McColl et al., 2014). Collocation studies, as presented here, often use a mixture of observations and numerical models. The term “data source” will therefore be used in the following to refer to different types of input data.
In this study the triple collocation approach is extended and adjusted with the special requirements of the coast in mind, where one can usually expect stronger gradients and smaller scale variations than in the open ocean. The objective of the study is to deal with the following four specific issues:
-
In the triple collocation method, different information sources within a certain distance are assumed to measure the same quantity, which can be unrealistic in regions with strong gradients, like most coastal areas.
-
So far, assumptions about correlation errors were made a priori (Vogelzang and Stoffelen, 2012), but they were not obtained as a result of the collocation process.
-
So far, no systematic approach was presented to deal with more than three data sources.
-
The quantification of uncertainties concerning estimations of systematic and stochastic data source errors was so far only done based on bootstrap approaches (Caires and Sterl, 2003).
The question about the accuracy of error estimates is of particular concern for new instruments, like Sentinel-3A, for which the amount of available data is still relatively limited. It is also clear that collocation distances are of concern mainly for point measurements or transect observations from satellites. The interpolation of numerical model data to given observation locations is usually less critical if the spatial resolution is appropriate.
The work presented here addresses the issues mentioned above and makes the following main contributions:
-
A generalisation of the triple collocation method is introduced, where the truth is not necessarily represented by a single number, but by a more general parameterisation of the truth state that is measured by a group of instruments within a certain distance. The analysis presented here concentrates on 1-D models (i.e. lines), and 2-D models (i.e. planes), but can be easily extended to include more sophisticated approaches.
-
In certain configurations, i.e. definitions of truth vectors and spatial distributions of data sources, the approach allows an estimation of cross covariance components of the stochastic errors contained in the considered observations or numerical models.
-
The theory includes the definition of a general data source vector, which can contain an arbitrary number of observations and numerical model data.
-
Analytical expressions are derived for the estimation errors regarding both systematic calibration errors and stochastic errors of the different data sources.
Like the standard triple collocation method, the extended approach also provides estimates of systematic bias and calibration errors. We will refer to the standard triple collocation method as “TRIPCOL”, and to the multi-collocation as “MULTCOL” in the following.
As an example for the generalised parameterisation of the truth, one can imagine two wave buoys and a satellite altimeter track passing between them. Let us furthermore think about a situation where the wave buoys are too far away from the track to assume that all three instruments measure the same quantity. However, it may be an acceptable assumption that the wave height measured by the altimeter is a linear combination of the wave heights observed by the two buoys. If independent numerical model wave height estimates are available at the buoy locations, the method presented in the following provides a systematic approach to estimate not only the stochastic errors of all data sets, but also the error correlation of the model at the buoy locations.
The present study is supposed to make a contribution to the exploitation of measurements with larger distances, where additional assumptions about the spatial variation in the truth are required. As an illustration, Fig. 2 shows maps of the North Sea with altimeter tracks and collocated buoys with the colour coding referring to the number of obtained collocated data samples within the period April 2016 to August 2017. The data sets will be introduced in more detail in Sect. 3. The plot Fig. 2a shows the situation if a collocation distance of 10 km is assumed as acceptable, whereas Fig. 2b shows the same with a collocation distance of 20 km. One can see that the number of data sets increases rapidly if larger distances are considered.
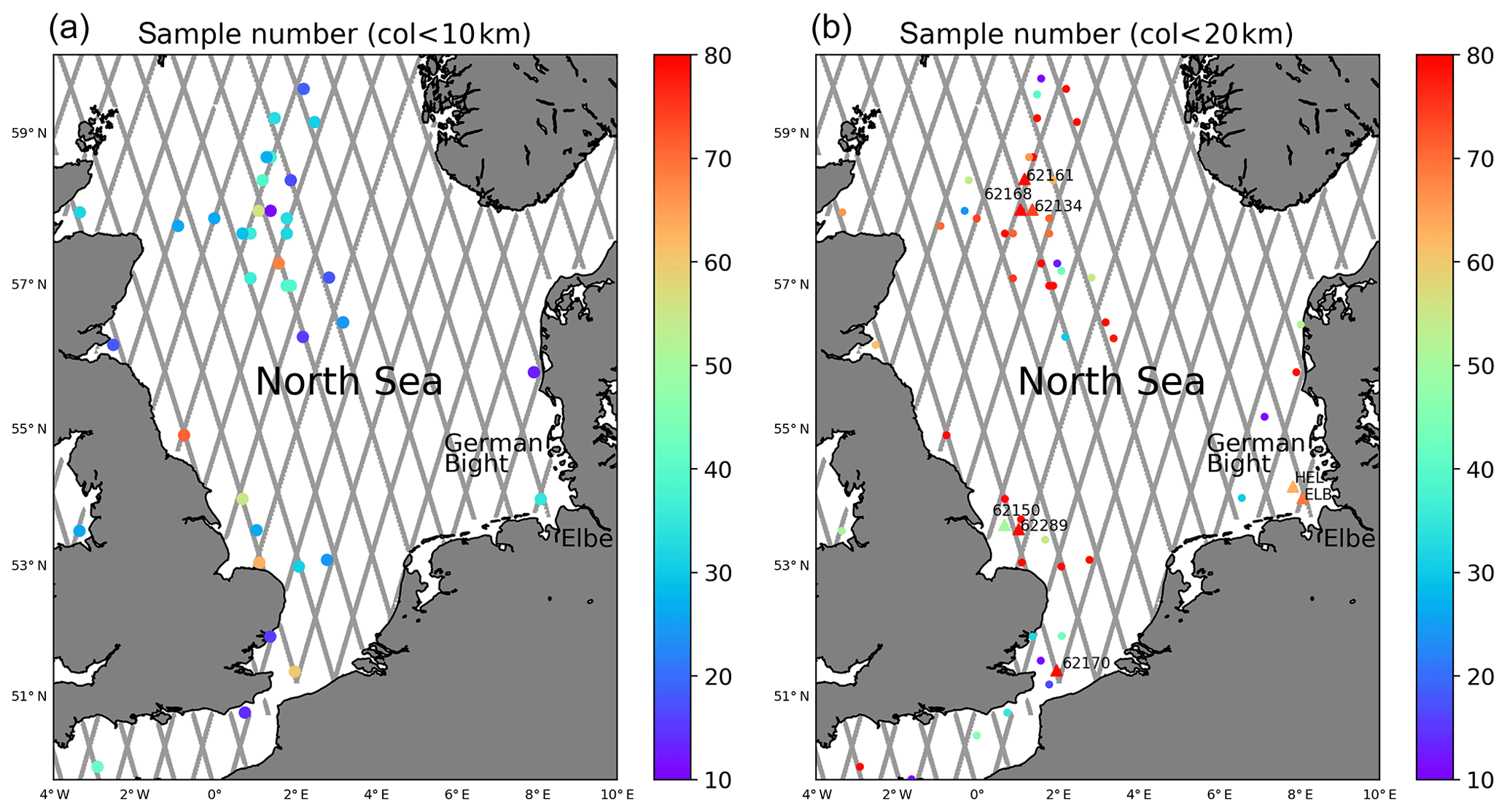
Figure 2(a) Map showing Sentinel-3A altimeter tracks together with wave observation platforms with less than 10 km distance to satellite measurements. The colour coding refers to the number of obtained collocated measurements in the period April 2016 to August 2017. (b) The same as (a) with a collocation distance of 20 km.
With regards to the estimation errors, expressions are derived which provide a quantification depending on the covariance matrices of the data sources, and the number of available data samples. These results can give valuable information on the trustworthiness of estimated observation errors, in particular in situations with a small number of samples.
The paper is structured as follows. The multi-collocation method is introduced in Sect. 2. This includes the explanation of the underlying theory for the treatment of the stochastic and systematic errors in Sects. 2.1 and 2.2, as well Monte Carlo simulations to illustrate and verify the method. In Sect. 3 the analysed significant wave heights from in situ stations, Sentinel-3A altimeter, and numerical model wave height data are introduced. As a special case of the multi-collocation method, the triple collocation technique is applied to the wave height data sets in Sect. 4. This includes a new step in the analysis, in which estimation errors are quantified. Section 5 describes the combination of more than three observations taken at a certain distance to estimate measurement errors and error correlations.
In this section the multi-collocation method is explained, which includes the triple collocation technique as a special case. In the first step, the approach for the estimation of the stochastic errors is presented, and in the second part systematic bias and calibration errors are considered.
2.1 Symmetric approach
The approach presented in this section to estimate stochastic errors does not require bias-free reference instruments. Calibration errors are not considered in this first step. Let us assume the truth is given by a vector t of dimension nt, and no data sources, , are related to the truth by
Here, A is an no×nt matrix; ϵ is an no-dimensional zero mean Gaussian process, which represents the stochastic data source errors; and b is a vector of length no containing the biases of the different data source components. Bold type is used for vectors. The triple collocation method is then a spacial case with nt=1, no=3, and . Here and in the following, the symbol T denotes the transpose operation. This case will be considered in Sect. 4 looking at a larger number of in situ observation locations in the North Sea. Using different definitions of the truth vector and the matrix A, various relationships between the truth and the data sources can be formulated with the above approach. In this study, we will concentrate on 1-D and 2-D linear models. It should be emphasised that the truth cannot, in general, be represented by a finite number of parameters. However, it is reasonable to assume that the reality is sufficiently smooth, and hence a Taylor expansion can be applied. The triple collocation method is then a special case, where only the constant term is considered. Depending on the number of available observations, the approach in Eq. (4) allows for the addition of higher-order terms. We will concentrate on linear approximations in this study; however, the method is able to deal with interpolation approaches of higher order if a sufficient number of data sources is available. Conceptually, this issue is related to the topic of representation errors (e.g. Van Leeuwen, 2015). The 1-D case will be considered in the Monte Carlo simulations presented in Sect. 2.5, as well as in Sect. 5.1. The 2-D case will be discussed in Sect. 5.2.
Let us now define a matrix B, which contains a basis of the null-space of A as rows. This can, for example, be obtained by singular value decomposition of A and selecting the eigenvectors corresponding to vanishing eigenvalues. If A has full rank, B is a matrix. For the triple collocation method this leads to
Multiplying Eq. (4) from the left by B gives
Averaging over all measurements then leads to
Forming the second-order moments results in
where we have a symmetric matrix on both sides of the equation. Because of the symmetry, one gets
equations. The right-hand side Z is of the form
Eq. (8) is therefore a linear system of equations of the form
where the vector ϵ contains the unknown variances and covariances of ϵ and r contains elements of the matrix on the left-hand side of Eq. (8). If it is possible to limit the number of unknowns to m, or less, using appropriate assumptions about the variance structure (e.g. independence of error components), this system can be solved when the corresponding system matrix D is regular. Table 1 summarises some feasible combinations of nt, no, and the number of error variances nvar and covariances ncovar that can be estimated if D is regular. Possible observation system configurations corresponding to these cases are shown in Fig. 3. Here, Fig. 3a corresponds to the standard TRIPCOL approach, where all data sources within a certain distance are assumed to measure the same truth. Linear approximations in 1-D and 2-D used in the MULTCOL approach, which relate data sources with a larger distance, are depicted in Fig. 3b and c, respectively.
Table 1The number of data source error variances nvar and covariances ncovar that can be estimated using different dimensions of the truth parameterisation nt, and number of data sources no according to Eq. (9).


Figure 3Illustration of three considered observation scenarios. (a) Data sources are assumed to provide information on the same quantity (0-D). (b) Measurements are located along a line and a 1-D linear approximation is employed for the measured quantity (1-D). (c) The same as (b), but using a 2-D interpolation method for more general spatial distributions of data sources (2-D).
If there are more equations than unknowns, a standard linear squares approach can be used to find a reasonable estimate for the unknown variance and covariance components of ϵ. It is interesting to note that this approach also works for biased measurements, although it is in general not possible to estimate the bias explicitly. All that is required is an estimate of Bb and this is easy to obtain via averaging of Eq. (7).
For the case of the triple collocation method, the system matrix D is in fact regular and the inverse is given by
For the triple collocation problem this leads to the well known expressions for the stochastic error variances (Janssen et al., 2007).
This corresponds to the “0-D” case in Table 1 and the geometry in Fig. 3a.
If the available number of samples ns is small, the estimated observation errors may be affected by large errors. To quantify these uncertainties at least in an approximate way, the covariance of the covariance estimator
is considered, where the stochastic vector is assumed to be Gaussian and zero mean. The covariance of these estimators for different pairs of (i,j) and can then be written as
Using standard relationships for the higher-order central moments of Gaussian-distributed variables (Triantafyllopoulos, 2003), this can be expressed as
The latter expression for can be used to estimate the variances and covariances in the estimation errors on the left-hand side of Eqs. (8) and (12), respectively. Therefore, the uncertainties in the estimated vector can be approximated by
From Eqs. (19) and (20) it is evident that observations with large variance and strong positive correlations will tend to lead to stronger estimation errors for . This is in particular the case when the geophysical background statistics already contribute a lot of variance, or when measurements are within the correlation distance of the background fields and the uncorrelated observation errors are relatively small. The usefulness of the approximation Eq. (20) will be considered in Sect. 2.3 based on Monte Carlo simulations.
2.2 Use of reference instruments
In this section a special, but also typical, situation is considered, where for a couple of measurements systematic errors can be neglected. Typically, this assumption is made for standard in situ observations systems, like waverider buoys (Janssen et al., 2007) or wind anemometers (Stoffelen, 1998). In this case, the error model for the different data sources can be formulated as follows:
Here, x represents the vector of reference measurements, and y contains the remaining data sources. In the examples discussed in the following sections, x will contain in situ wave height measurements and y will represent a combination of satellite altimeter and numerical wave model data. The dimensions of x and y are denoted by nx and ny in the following. The matrices Ax and Ay translate the truth vector t to the expected reference measurements x and the other data sources y. In addition, it is assumed that the matrix Ax is invertible, i.e. it is possible to obtain an estimate of the truth vector t from the observations x. The matrix I is the identity matrix. Apart from a possible bias, the vector of data sources y may be also affected by systematic calibration errors represented by the diagonal matrix λ.
To obtain expressions for the scaling parameters contained in λ, the first- and second-order moments of the input data x and y are considered. For the first-order moments Mx and My of x and y, one gets
The second-order moments Mxx and Myy follow as
The covariance functions Cxx and Cyy can then be written as
and the cross covariance Cxy between x and y as
The equation for Cyy then gives
This results in ny equations for each scaling component according to
where νiq are the elements of the matrix .
Let us assume for a moment that the scaling parameters λ are available. One can then derive the bias of y from Eq. (23). Furthermore, defining the matrix A in Eq. (4) as
the approach in Sect. 2.1 can be applied to estimate the stochastic errors of the different data sources.
There are now two basic approaches to estimate the scaling parameters.
-
Direct method: Those terms in Eq. (32) are used for which 〈ϵiϵj〉 is known, e.g. because the error components are assumed independent. In this case the estimation of the observation errors and the scaling parameters are independent and can be treated separately.
-
Iterative method: Terms in Eq. (32) are used for which 〈ϵiϵj〉 is not known a priori. In this case an iterative method has to be used, where the estimation of the data source errors and the scaling parameters are performed in succession until convergence is achieved. Similar iteration techniques were also discussed for the triple collocation method in Janssen et al. (2007) and Vogelzang and Stoffelen (2012).
In Janssen et al. (2007) an iterative method had to be applied for the triple collocation analysis, because the proposed procedure for the scaling parameter estimation leads to a non-linear expression, which could not be treated in a direct way. The direct method for the standard triple collocation problem leads to the known expressions (Caires and Sterl, 2003):
One can see that for the estimation of no use is made of correlations between y1 and x1, which may contain a lot of useful information. This can be overcome by the iterative version with
In some cases, there may be several equations for one component of λ, and it is then important to have an approximation for the respective estimation errors to pick the estimator with the smallest variance. Quantification of these uncertainties is also of general interest in the statistical analysis of data, in particular if the sample size is small. For the analysis in this study, we only consider the direct method, where the 〈ϵiϵj〉 in Eq. (32) are known constants. We also do not consider the additional uncertainty, which is caused by estimation errors for these stochastic error variances and covariances. Denoting the nominator and denominator in Eq. (32) by Ω1 and Ω2, a Taylor expansion gives
For the variance one gets
The variances and covariances in Ω1 and Ω2 can be derived by making, again, use of Eq. (19).
2.3 Generation of background statistics
In the following, the techniques presented in Sects. 2.1 and 2.2 will be assessed and validated based on synthetic observations for which the observation errors are known a priori. This requires Monte Carlo simulations for which realistic background statistics are desirable. Here, we use parameters derived from an 11-month time series of two buoys in the German Bight. The buoys “ELB” and “HEL” can be identified in Fig. 1 as the instruments closest to the entrance of the river Elbe. The buoy HEL is near the island Heligoland at about 25 m water depth and about 30 km north-west of the buoy ELB, which is at about 27 m water depth. The wave height distributions of both buoys shown in Fig. 4b and c indicate a shape, which can be very well approximated with a log-normal distribution superimposed as green curves. The joint distribution in Fig. 4a shows a quite good correlation between the data sets, which is expected due to the relative close proximity of the buoys. The histogram of the difference between the Elbe buoy and the Heligoland buoy shown in Fig. 4d indicates that the majority of cases have higher waves at the Heligoland location than the Elbe location. This makes sense because north-westerly winds are predominant in the area. Therefore, situations with waves coming from offshore and being dissipated by wave breaking and bottom friction are most often observed in the German Bight. The fewer cases with higher waves near Heligoland are associated with southerly winds, where waves are actually generated near the coast and the wave height increases with fetch length. The respective parameters for the log-normal distribution including the correlations of both buoy time series are given in Table 2.
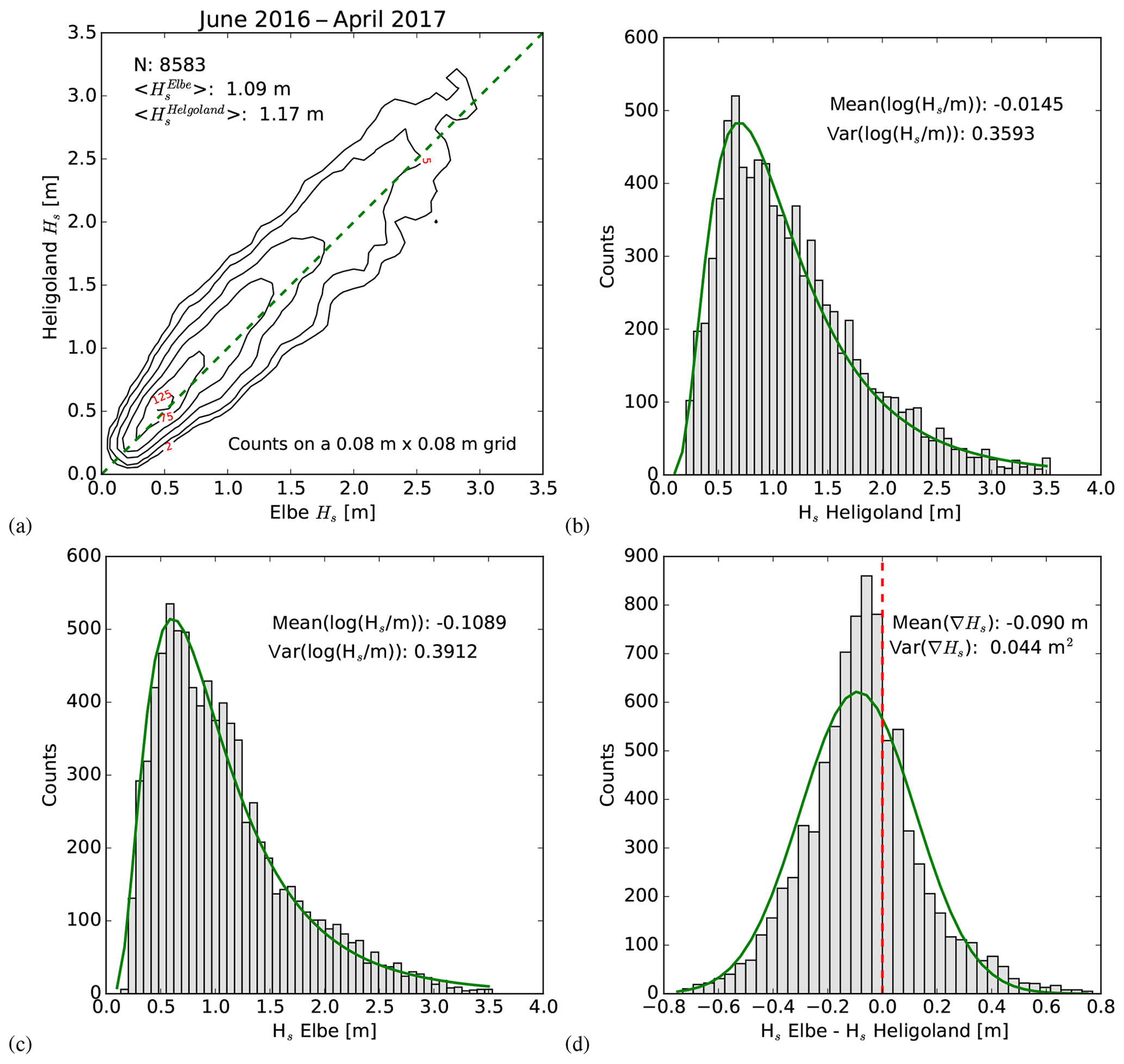
Figure 4Background statistics used for the Monte Carlo Simulations. (a) 2-D histogram of the joint distribution for the Elbe and Heligoland buoys derived from the period June 2016–April 2017 with diagonal given as a dashed green line and the black isolines referring to probability density. (b) 1-D histogram for the Heligoland buoy wave heights with log-normal probability density function (pdf) superimposed in green. (c) The same as (b) for the Elbe buoy. (d) Histogram of the difference between the Elbe and Heligoland wave height with Gaussian pdf superimposed in green, and the dashed red line indicating the zero position.
Table 2Mean, variance (var), covariance (covar), and correlation (corr) parameters used for the simulation of the background wave height statistics at the locations of the Heligoland and Elbe buoys in the German Bight. These numbers were derived from measurements taken during the period June 2016–April 2017. The respective probability distributions with a log-normal approximation are shown in Fig. 4.

2.4 Impact of coastal gradients and spatial data set resolutions on triple collocations
In this section a brief analysis is presented concerning the impact of coastal gradients on the standard triple collocation approach and the role of spatial data set resolutions. The analysis is illustrated using the background statistics presented in Sect. 2.3.
As explained before, the triple collocation method makes the assumption that all three data sets represent the same truth. We consider the case now, where this assumption is violated, and where we have data sets representing the wave height at three different locations x, x′, and x′′. Let us denote the wave heights at the three locations by
where , and are the respective mean values, and , and are the departures from the mean. Furthermore, it is assumed that the three wave height data sets are affected by uncorrelated additive zero mean errors , and . According to Eq. (14), the measurement error of the data source corresponding to location x would be estimated as follows if the standard triple collocation method is applied:
The angle brackets refer to averages over different realisations of the background state and data source errors. As one can see, the estimation of is affected by an error which has two components. The term Rx is related to correlations of wave height differences in the background statistics. In situations where all three data sources are in a region with a spatial wave height gradient, typically observed in coastal areas, this term will not vanish, at least as long as the data sources are located along the gradient. The term is related to the differences in mean wave heights at the three locations. This term can be expected to contribute to the estimation error in coastal areas as well.
We are now estimating these error contributions for the background statistics derived in Sect. 2.3. Let us assume that the wave height along a straight line between the stations HEL and ELB can be approximated reasonably well with a linear function, i.e.
where x denotes the distance of some point X from the Elbe station in the direction of Heligoland; HHel and HElb are the wave heights at the Heligoland and Elbe stations; and d=24 km is the distance between the two stations. Defining and analogues to Eq. (40), we get for the wave height covariance of two points
where α1=0.000147, α2=0.003174 m, and α3=1.7529 m2 for the considered case. With this information Eq. (41) can be evaluated. For the spatial distribution of the three data sources we assume that x=10, , and km, i.e. all three data sources are within 10 km distance. The resulting errors for the triple collocation method then follow as (see Eq. 41):
If an instrument at location x is considered, which has a truth observation error standard deviation of m, these error terms would lead to an estimation error by the triple collocation method of about 40 % in terms of variance. If the collocation distance is increased to 20 km, and one has data sources at x=10, , and km, the following error is obtained:
In this case the collocation error grows to 160 % with respect to the truth observation error. As explained in Sect. 2.1, the multi-collocation method proposed in this study is designed to take spatial gradients, as discussed above, into account; however, this is at the cost of requiring a larger number of data sources. This will be illustrated in Sect. 2.5 using the same background statistics.
The second issue to be discussed in this section is the role of the spatial resolution of the different models and observations. The main point to consider here is that sub-resolution variations in wave height become part of the estimated data set error if the triple or multi-collocation methods are applied. This has two main consequences:
-
The estimated data source errors are influenced by the background statistics.
-
For two data sources with a common unresolved band of spatial scales, the data source errors are correlated (Vogelzang and Stoffelen, 2012).
In general, the expected unresolved sub-resolution variance in wave height is given by
where A is the resolution cell of the assumed data source and the respective data source wave height is computed as
where is the truth wave height at location x′ within the resolution cell. We now evaluate these terms, again using the background statistics presented in Sect. 2.3. For simplicity, we assume that the resolution cell is one-dimensional and spans from the Elbe station (x=0) to some point x=a in the direction of Heligoland. The data set then corresponds to averages of the form
The mean unresolved variance within one resolution cell can then be written as
One can see that the mean sub-resolution variance is depending on the mean gradient, as well as the variance in the gradient within the resolution cell. Using the background statistic values in Sect. 2.3, the variance was computed for different values of the cell size a. For a=5 km one gets m2, for a=10 km the result is m2, and a=20 km gives m2. Let us imagine an observation instrument located at with a measurement error standard deviation of 0.1 m. This value is supposed to only describe the instrumental errors, i.e. the errors that one always has, even if the wave height within the resolution cell is constant. Furthermore, assume that the observations represent averages over wave heights in the resolution cell of size a as described by Eq. (48). For a=10 km this averaging process adds about 10 % to the data set error variance, and for a=20 km this increases to 50 %.
The above analysis has shown that both the collocation distance and the spatial data set resolutions are important factors for the quantification and interpretation of the respective data set errors. The separation of instrumental errors and sub-resolution-related errors is a challenge, because it requires knowledge about the truth background wave statistics on a sub-resolution scale. In general, such information can only be obtained if one of the data sources has a significantly higher spatial resolution than the other data sources.
2.5 Monte Carlo simulation for the 1-D case
As an example, we consider the case where we have data sources which are approximately located along a straight line. This corresponds to the scenario depicted in Fig. 3b. We approximate the truth state by a linear model with two parameters. From Eq. (9) it follows that we need at least five data sources to estimate the errors. Let us assume we have two buoys, a satellite altimeter with two measurements close to the buoys, and a numerical model estimate in the middle between the two buoys. Using the wave heights at the buoy positions as the state parameters t one gets
for the matrix A, which relates the truth vector to the observations (see Eq. 4). Here, we have assumed a geometry as depicted in Fig. 3b. The first and second row of A refer to the two buoy measurements, which are assumed to be without systematic errors. The third and fourth row correspond to the two altimeter measurements near the ELB buoys and the HEL buoy, which are assumed to be affected by calibration errors with scaling parameters of 1.2 and 1.3. The last row represents the wave height estimate provided by the wave model in the middle between the two buoys. The model is assumed to have a calibration error with a factor of 0.9.
The Monte Carlo experiments were then performed as follows:
-
120 observation vectors y were created using a random simulator with prescribed variances and covariances for the background statistics and the observation errors.
-
The observation errors and their uncertainty were estimated using the approach described in Sect. 2.1.
-
These experiments were repeated 1000 times to obtain statistically robust results.
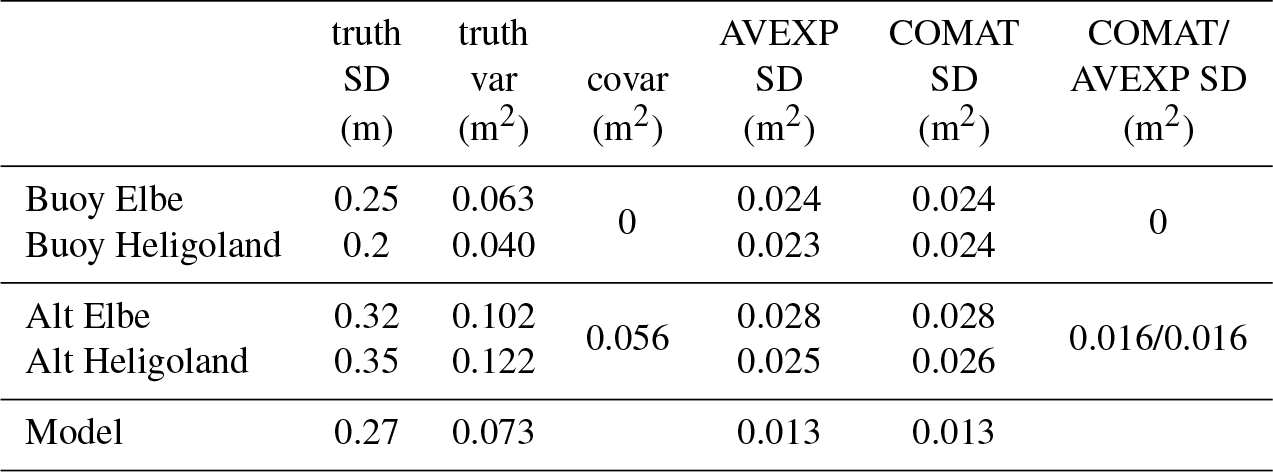
The parameters used for the simulations, as well as the obtained results, are summarised in Table 3. The first three columns refer to the assumed observation error statistics for the buoys, the altimeter, and the numerical model. One can see that a covariance of 0.056 m2 was used for the two satellite measurements, which corresponds to an error correlation of 0.5. The last three columns refer to the estimation errors, which were obtained in two different ways:
-
The uncertainties are estimated directly by computing the variance of the estimated observation errors over all experiments. This is called the “averaged experiments” approach (AVEXP) in the following.
-
The uncertainties were estimated for each experiment from the input data covariance matrices as explained in Sect. 2.1. These estimates were than averaged over all experiments. This is called the “covariance matrix” approach (COMAT) in the following.
For the obtained data source errors averaged over all experiments, the numbers agree with the assumed errors to within three decimals, which illustrates the validity of Eq. (12). The same is also true for the estimated uncertainties for the variances and covariances estimated from Eq. (20). The last three columns in Table 3 show that the covariance matrix method and the numbers from the averaged experiments are in very good agreement. The last column contains the respective comparison for the covariance of the altimeter measurement errors, where the two approaches also give very consistent results. Overall, these results confirm that the estimation of uncertainties in the estimated stochastic errors by Eq. (20) is a reasonable approach.
Table 3Parameters used for the Monte Carlo simulations in Sect. 2.5. The first two columns refer to the stochastic wave height error standard deviation (SD) and variance (var) assumed for the considered data sources. The third column gives the assumed error cross covariance (covar) values for the two altimeter measurements and the two buoy data sets. The fourth column is the error standard deviation of the estimator for the observation error variances obtained by averaging over 1000 estimation experiments (AVEXP approach). The values in column five refer to the same estimation errors, but derived by application of the method described in Sect. 2.1 (COMAT approach). The last column gives the COMAT and AVEXP standard deviations for the covariance estimation errors.
In a second step the same exercise was done for the estimation of the systematic errors. The first column of Table 4 shows the assumed calibration errors, i.e. scaling parameters used in the generation of the synthetic observations. In this case the estimated calibration factors averaged over all experiments shown in the second column agree with the theoretical values to within two decimals, which seems reasonable. The values for the estimation errors obtained with the COMAT approach (third column) and the AVEXP approach (fourth column) are also in good agreement, considering that several approximations (e.g. Eq. 38) were used.
Table 4Parameters used for the Monte Carlo simulations to validate the approach described in Sect. 2.2 for the quantification of errors in the calibration factor estimates. The MULTCOL technique is applied to a 1-D configuration with five data sources, of which three (two altimeter (Alt) observations and one model estimate) are affected by calibration errors. The first column gives the assumed truth scaling parameters and the second column gives the respective estimates. The last two columns represent the uncertainty estimates for the derived scaling parameters in terms of standard deviation (SD) based on two different procedures. See text for details.

In this section the observation and numerical model data used for the multi-collocation analysis are introduced. The data sets are from the period April 2016 to August 2017.
3.1 Satellite altimeter data
The satellite data used here were taken by the European satellite Sentinel-3A launched in February 2016. The satellite flies on a sun-synchronous orbit with an exact repeat cycle of 27 days. The spatial accuracy of the revisit is ± 1 km in the longitudinal direction. Among other instruments, the platform hosts a radar altimeter (SRAL) operating at Ku and C bands (Le Roy et al., 2007). The main frequency used for range measurements is in the Ku band (13.575 GHz), while the C-band frequency (5.41 GHz) is used for ionospheric correction. The basic footprint of the altimeter antenna is a disc with approximately 20 km diameter. However, the effective area actually influencing the measurements is more narrowly centred around the nadir point with a diameter of about
Here, R0=814 km is the altitude of the satellite, Re is the radius of the earth, c is the speed of light, τ is the pulse duration, and Hs is significant wave height (Chelton et al., 1989). For the typical pulse durations of the order of 3 ns, the effective footprint varies between 1 and 10 km with larger footprints at high sea states. In particular in coastal areas, the altimeter data processing is quite involved (Chelton et al., 2001), and a number of instrument and processing parameters can have a strong impact on the characteristics of the wave height estimates.
In this study Sentinel-3A data with 1 Hz sampling are analysed, which correspond to measurements taken every 7 km along the track. The analysed data were acquired in the so-called reduced synthetic aperture radar (RDSAR) mode, which provides data comparable to measurements from a traditional satellite altimeter. A comparison of different Sentinel-3A altimeter modes can be found in Wiese et al. (2018).
Figure 2a shows the distribution of Sentinel-3A tracks over the North Sea. “Ascending” passes are from south-south-east to north-north-west, whereas “descending” passes are from north-north-east to south-south-west.
3.2 In situ measurements
In this study in situ wave height measurements distributed over the Global Telecommunication System (GTS) were used, which are archived at the European Centre for Medium-Range Weather Forecasts (ECMWF; Bidlot and Holt, 2006). Additional wave observation data were gathered by ECMWF as part of the JCOMM Forecast Verification project (Bidlot et al., 2002). These measurements have a quite inhomogeneous geographical distribution as shown in Fig. 2. As one can see, the focus of the observations is on coastal areas and regions with intense offshore activities, like the northern part of the North Sea. Some of the in situ stations shown in Figs. 1 and 2b, which are referenced in the subsequent analysis, are labelled by either 5 digit numbers (e.g. 62168) or three character strings (e.g. ELB). Due to the lack of respective metadata, it was not possible to distinguish between different types of instruments, e.g. waverider buoys or platform-mounted devices. One exception is the station 62170 near the east English Channel entrance, which is identical to the light ship “F3” mentioned in Anderson et al. (2016). In addition to the GTS data, in situ wave measurements taken in the German Bight were obtained from the Bundesamt für Seeschifffahrt und Hydrographie (BSH). The GTS data have a temporal sampling of 1 h, while the BSH buoys provide observations every 30 min. The in situ observations represent raw values and were checked for unrealistic wave heights. Looking at all the in situ stations for the analysed period in summary, the provided significant wave heights were in the range between 0.1 and 7.8 m. These are realistic values for the North Sea (Semedo et al., 2015) and hence all observations were used in the analysis.
3.3 Wave model WAM and meteorological input data used
For this study, data generated with the spectral wave model WAM were used (Komen et al., 1996). The model version cycle 4.6.2 considered here includes depth refraction and wave breaking and is therefore suitable for coastal applications (Staneva et al., 2017). Spatial variations in bathymetry are taken into account; however, temporal variations in water depth due to tides are not included in the simulations. The 2-D-wave spectra are calculated on a polar grid with 30 directional 15∘ sectors and 30 logarithmically spaced frequencies ranging from 0.042 to 0.66 Hz. A spherical grid is used for the space dimensions with ∼0.06∘ resolution in zonal and ∼0.03∘ resolution in meridional direction. The required forcing at the open boundaries of the North Sea model domain are derived from a coarser model simulation for the whole North Atlantic. Model output with 1 h time steps was available for the analysis. ERA-5 data are used as meteorological forcing for the North Sea model runs (Hersbach and Dee, 2016). This data set is a global re-analysis product from ECMWF with a spatial resolution of 31 km. The model results are interpolated to a 0.25∘ grid, and the time step is 1 h in the final product. A detailed comparison of different model setups with satellite altimeter data can be found in Wiese et al. (2018).
Compared to previous studies (Janssen et al., 2007; Caires and Sterl, 2003), the spatial resolutions of the three analysed data sources are in quite close agreement. The effective resolutions of the altimeter and the in situ instruments both depend on the actual sea state. For the altimeter typical footprint sizes are between 1 and 10 km as explained in Sect. 3.1. For the in situ data, the translation of the typical 20 min averages to spatial averages is determined by the group velocity. For example, the energy will propagate with about 15 km h−1 if the dominant wave length is 50 m long and the water is deep (>50 m). A 20 min temporal average would therefore correspond to a 5 km spatial average in this case, which is in good correspondence to the spatial model resolution of about 3.5 km. We have therefore used the original data for the analysis and not generated super-observations by averaging, as done in Janssen et al. (2007) and Caires and Sterl (2003), who used wave model data with significantly coarser resolution.
In this section the triple collocation method, as a special case of the multi-collocation approach, is applied to the Sentinel-3A altimeter wave height measurements introduced in Sect. 3.1 to assess the respective systematic and stochastic errors. The novelty lies in the analysis of a new satellite data set and the provision of error bars for the estimated stochastic and systematic errors.
Traditionally, validations of new data sets are performed by comparing to data from established in situ measurements, which are regarded as a reference. Here, the following assumptions are made:
-
Sentinel-3A and the WAM model may be affected by calibration problems represented by the calibrations factors λS3 and λWAM.
-
Sentinel-3A and the WAM model may be affected by biases bWAM and bS3.
-
Buoys are regarded as reference systems, i.e. they are assumed as bias free and without calibration errors.
Each of the Sentinel-3A tracks shown in Fig. 2a is passed by the satellite about once a month. Figure 2b shows the respective number of collocations found if a maximum distance of 10 km is accepted. The collocation involves some necessary interpolation steps, which were performed as follows (Janssen et al., 2007):
-
The model is interpolated to the buoy using linear interpolation.
-
The model is interpolated to the closest altimeter point using linear interpolation.
-
Both the buoy and the model are interpolated to the satellite overflight time.
-
The model value used for the location is taken as the average of the buoy and the satellite interpolation (see Janssen et al., 2007).
The triple collocation technique was applied to each in situ platform for which altimeter data within the acceptable collocation could be found. The direct method as described in Sect. 2.2 was used for this analysis.
As an example, Fig. 5 shows the obtained results for the Elbe buoy ELB located at 54.0∘ N 8.1∘ E. The location of this buoy can also be found in Fig. 1. The three scatter plots show the used data sets in different combinations (buoy versus WAM, Fig. 5a; buoy versus Sentinel-3A, Fig. 5b; and WAM versus Sentinel-3A, Fig. 5c). The three data sets were corrected according to the slope and bias parameters estimated in the collocation procedure. The slope parameters for both the model and Sentinel-3A were found to be below 1, and there exists a larger positive bias for the altimeter. The red triangles correspond to ascending satellite passes and green triangles indicate descending satellite heading. A connection between the satellite flight direction and errors is not clearly visible. This is an important result, because the altimeter data processing is known to be more challenging for passes going from land to sea. It is evident that the best agreement is between the buoy and the model. The smallest stochastic error is found for the buoy with 0.04 m standard deviation. For this location, the collocation procedure gives the largest stochastic error of 0.25 m for the altimeter data.
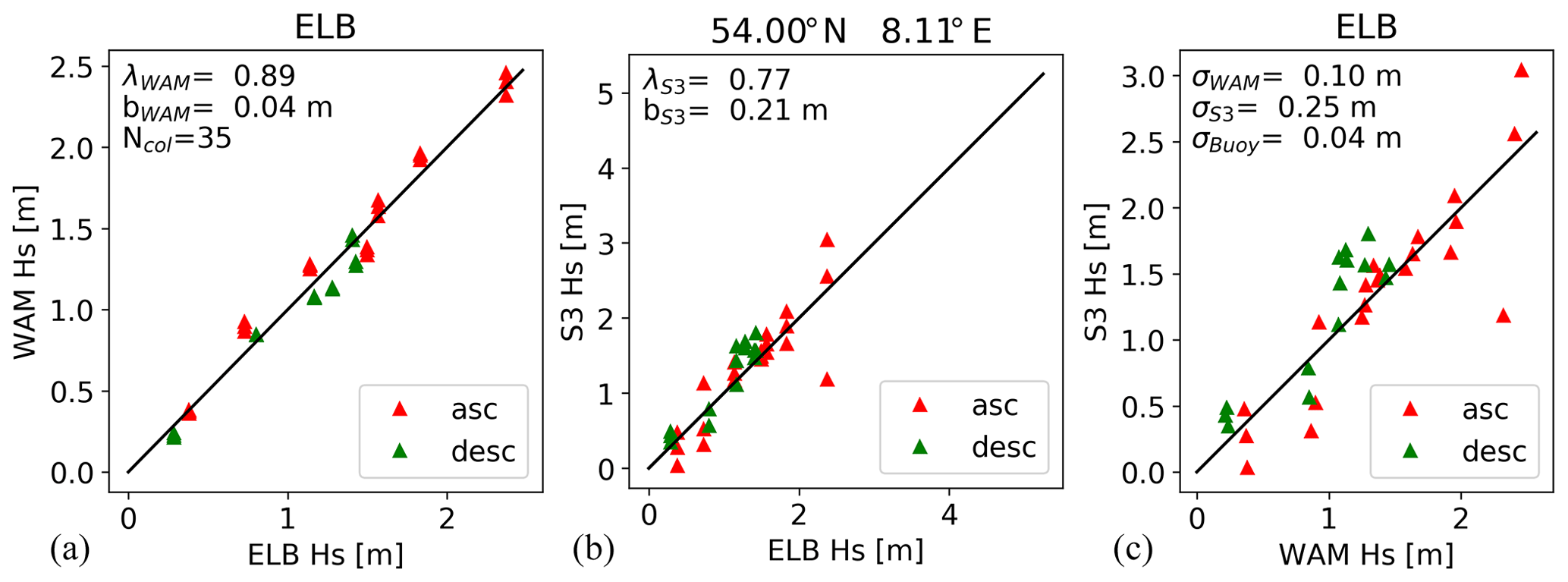
Figure 5(a, b) Comparison of wave heights measured by the Elbe buoy with numerical model results (a), and Sentinel-3A altimeter measurements (b). The model and satellite data sets were corrected according to the calibration factors λWAM and λS3 and bias parameters bWAM and bS3 estimated in the triple collocation procedure (see Eq. 21). (c) Direct comparison between model and satellite data. Numbers are given for the estimated calibration factors, bias, and stochastic error standard deviations ϵWAM, ϵS3, and ϵBuoy. The red triangles refer to ascending (asc) satellite passes and the green ones to descending (desc) passes.
Figure 6 shows the estimated biases (Fig. 6a and d) for the Sentinel-3A altimeter (Fig. 6a, b, c) and the wave model (Fig. 6d, e, d). One can see that the altimeter seems to be either bias free or slightly biased high for most of the cases (Fig. 6a). Averaging over all buoys gives a bias estimate of
Concerning the spatial distribution of observation errors, it is hard to draw a conclusion. It is, however, evident that the few cases with low bias are far offshore (Fig. 6a). For the wave model there a few more cases where a small low bias is found (Fig. 6d). Again, averaging over all buoys gives
The spatial distribution shows a weak clustering of low-bias cases in the northern part of the North Sea. It is interesting to note that for the location of the light vessel 62170 near the east entrance of the English Channel (see Fig. 1), the satellite and the model show a positive bias of about 0.3 and 0.2 m, respectively. According to Anderson et al. (2016), one can expect a systematic low bias for wave height measurements from light vessels of about 0.3 to 0.4 m. It is thus possible that the estimated high bias for satellite and model is in this case an artefact caused by the violated assumption of bias-free in situ observations.
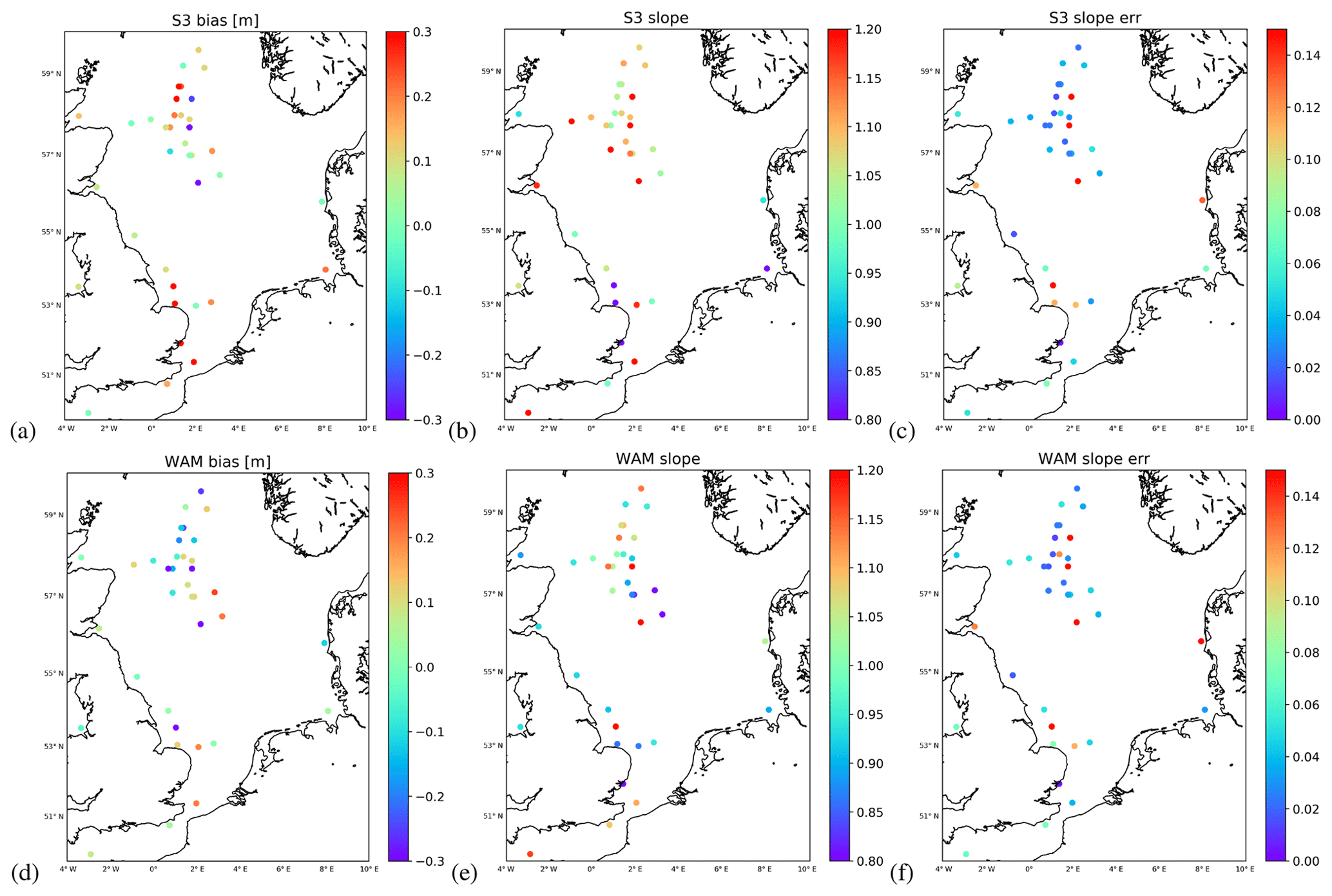
Figure 6Colour coded biases (a, d) and calibration factors (b, e) derived by triple collocation for the Sentinel-3A altimeter (a, b, c) and WAM model wave heights (d, e, f). The right column (c, f) gives the uncertainties in the slope estimations derived using the approach in Sect. 2.2 as standard deviation.
The scaling parameter for the satellite altimeter shown in Fig. 6b indicates values above 1 for most of the cases. In fact, averaging over all buoys gives
The respective scaling parameter estimation errors derived using the approach described in Sect. 2.2 are shown in Fig. 6c. It is evident that quite a few of the cases with exceptionally high scaling values (around 1.2) are affected by large estimation errors. This is a good illustration of the added value provided by the error estimation procedure presented in this study. The corresponding scaling parameters for the WAM model shown in Fig. 6e show values which are closer to unity for the most part. The respective mean value is
with higher values (around 1.1) found in the English Channel. Most of the other cases closer to the coast have slope values slightly below unity. Most of the cases with large estimation errors for the scaling factor (Fig. 6f) are found close to the coast.
Results for the stochastic errors are summarised in Fig. 7. The columns refer to Sentinel-3A (Fig. 7a and d), the WAM model (Fig. 6b and e), and the buoys (Fig. 6c and f). Figure 7a, b, and c show the estimated stochastic error standard deviation and the Fig. 7d, e, and f the respective relative estimation errors ν, defined as
where 〈ϵ2〉 is the error variance, and SD(〈ϵ2〉) is the standard deviation of the respective estimator, derived using the approach described in Sect. 2.1. One can see that, overall, the smallest stochastic errors are found for the buoys, as expected (Fig. 7c). In fact, one gets
averaging over all buoys. There are two buoys which stand out with errors above 0.25 m in the northern part of the North Sea. In this case, the estimation errors are not exceptionally high and possible reasons for these relatively high error levels should be further investigated. In general, one can see that the estimation errors are quite large, exceeding in most cases 20 % (Fig. 7f).
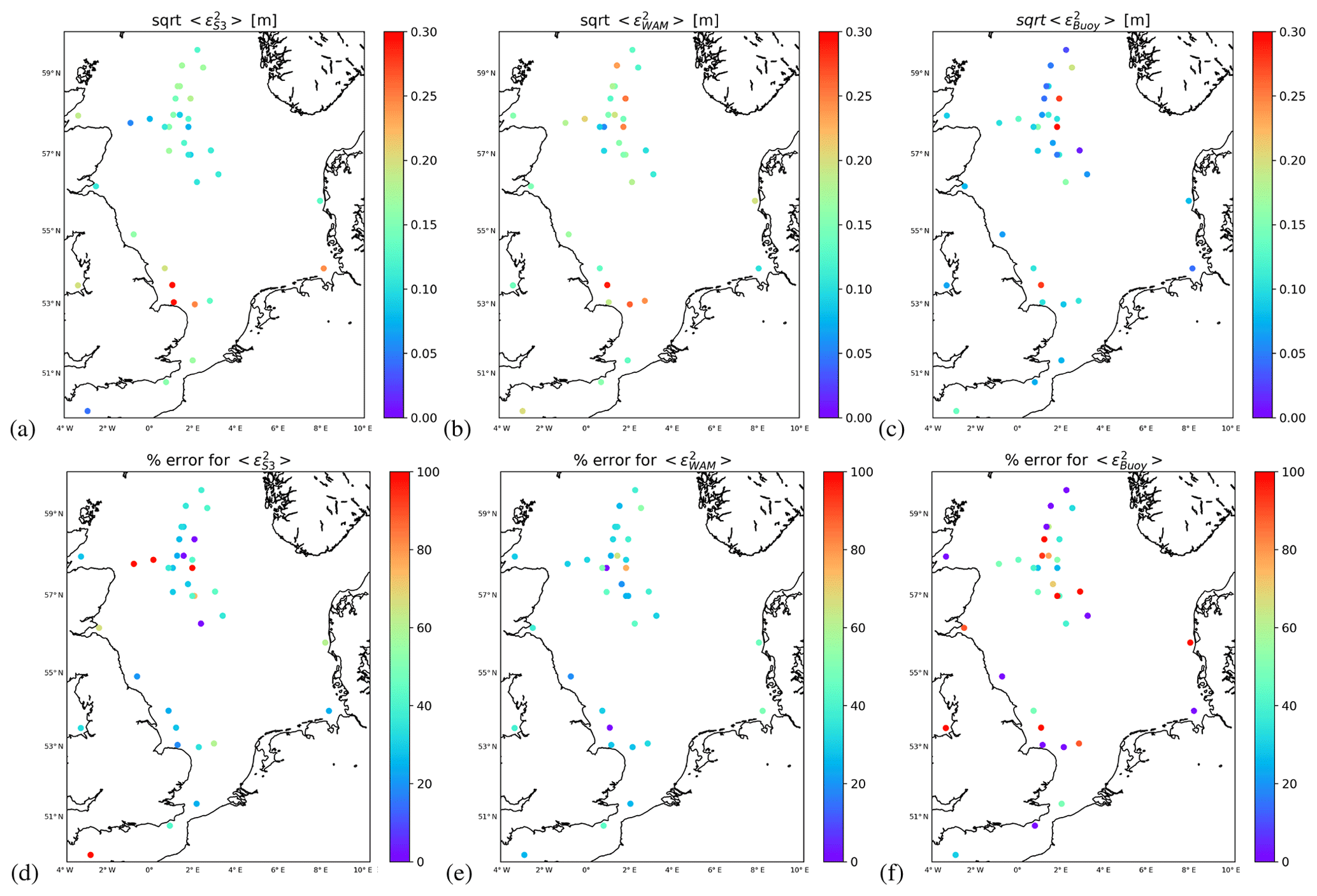
Figure 7(a, b, c) Colour coded stochastic error standard deviations of wave heights provided by the Sentinel-3A altimeter (a), the WAM model (b), and the in situ stations (c) estimated by triple collocation. (d, e, f) Relative uncertainties in the stochastic error estimates derived by using the approach in Sect. 2.1.
The stochastic errors of the WAM model (Fig. 7b) and the altimeter (Fig. 7a) are quite similar in their average values
It is interesting to see that the two buoys mentioned above also stand out with respect to the corresponding model errors. Theoretically, this could be due to a correlation between the background statistics and both the model and buoy errors. However, because this is observed in a quite homogeneous offshore area, with neighbouring buoys not showing the same effect, this explanation is not very likely. It is more likely that the basic assumptions about zero bias or absent calibration errors are violated for these buoys.
The finding that, on average, the in situ stations have the smallest stochastic errors is at first sight in disagreement with results presented in Janssen et al. (2007). One has to take into account, however that there are a number of significant differences in the analysis. First of all, a global wave model with 55 km resolution was used in the former study, whereas the computational model grid used in our analysis has a resolution more than 15 times higher. It is unlikely, however that the coarser model resolution is the only factor, because Caires and Sterl (2003) also concluded that the in situ stations have the smallest stochastic errors using wave model output with even coarser resolution (1.5∘) than used by Janssen et al. (2007). Both studies introduced altimeter super-observations (averages over subsequent measurements) to make the altimeter observations more consistent with the model estimates. In the present study this was not considered necessary, because the altimeter and model resolutions are in much closer agreement. The second major difference with respect to previous studies is the geographic locations and the type of altimeter data considered in the analysis. Janssen et al. (2007) investigated global ERS-2 and Envisat altimeter data sets, while Caires and Sterl (2003) concentrated on TOPEX and ERS-1 altimeter data acquired over the Pacific and the US east coast. This means that there are certainly differences both with regard to the background wave statistics and the satellite and in situ observation errors. A third important difference between the studies is the applied collocation criteria. Janssen et al. (2007) required the model, in situ, and satellite estimates to be within 200 km distance and Caires and Sterl (2003) used a smaller collocation distance of 0.75∘. The allowed distance of 10 km used in the present study is still significantly smaller than that, and the collocation errors are therefore also likely to be smaller. For the above reasons, one cannot conclude that the present study contradicts the results in Janssen et al. (2007). The conclusion is rather that a common set of reference in situ data and collocation criteria are desirable to make different studies more comparable.
It is evident that the observed heterogeneity of in situ measurements is a big complicating factor in the analysis. Wave model computations and satellite altimeter observations have reached a level of accuracy where further improvements require a very careful selection and treatment of validation data sets. This in particular requires more knowledge about the type of in situ instruments and applied data processing techniques (e.g. averaging intervals). This could also be an argument for investments into dedicated validation instruments with more transparent and better documented error characteristics and quality control. The deployment of such instruments should take into account both research aspects and requirements for operational use.
In this section different examples are presented where more than three observations are combined, i.e. this is beyond the standard triple collocation approach. The two examples discussed in the following are typical situations encountered when analysing in situ data, model data, and satellite measurements in combination.
5.1 1-D example
The geometry of the first example is depicted in Fig. 8a. Here, an ascending Sentinel-3A track passes between the two in situ stations 62150 and 62289. The station on the easterly side is within 10 km distance of the track and was therefore used in the triple collocation study presented in Sect. 4. Station 62150 did not match the criteria and was disregarded for the analysis. Both stations can be found in Figs. 1 and 2b, where they are indicated by triangle symbols.
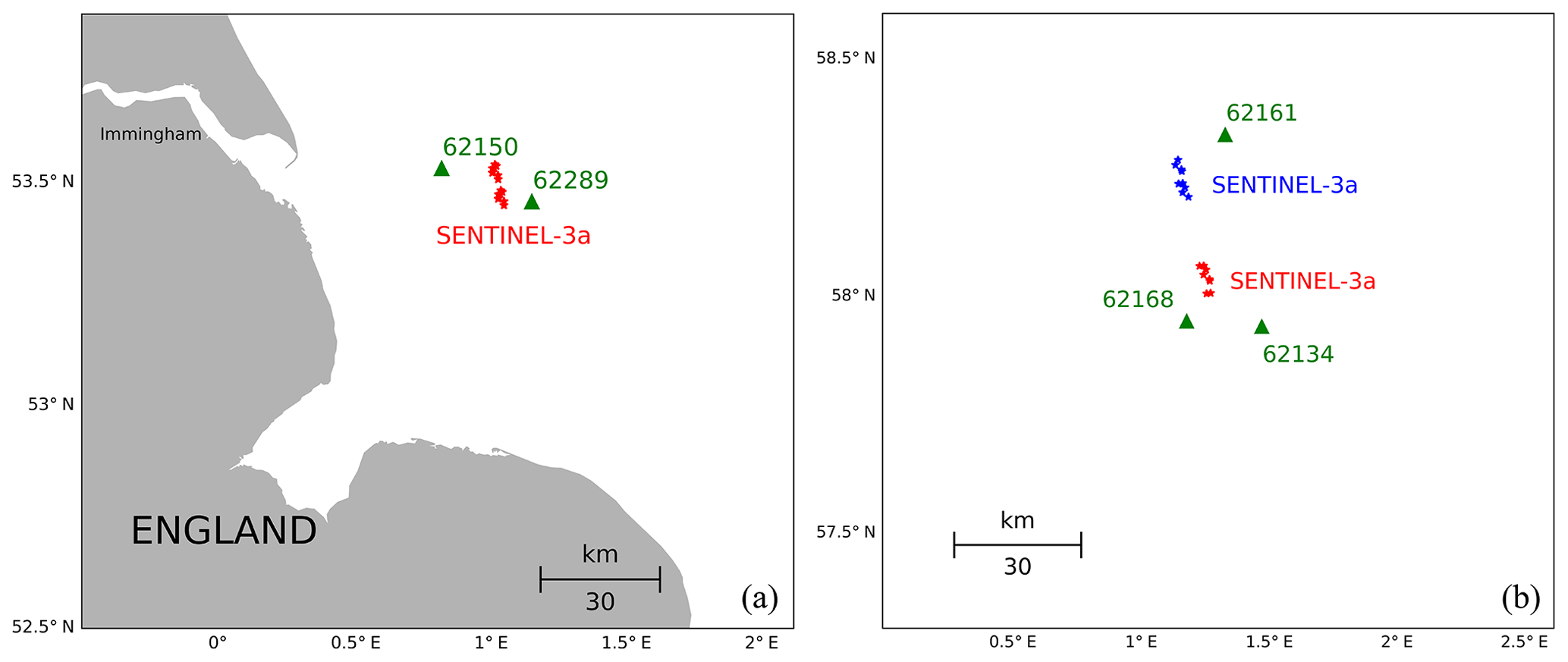
Figure 8(a) Example of observation configuration with a descending Sentinel-3A altimeter track passing between two in situ wave observation instruments (62150 and 62289), (b) Observation geometry with Sentinel-3A track passing through a group of three in situ wave measurement devices. The blue and red altimeter measurements are used to estimate error correlations for both the altimeter and the numerical model.
The idea to relate both in situ measurements to the altimeter track is to use a linear interpolation of the truth wave height between the two stations, which makes the use of the instrument with the larger distance more acceptable in the collocation procedure. In principle, this corresponds to the 1-D case depicted in Fig. 3b with the role of altimeter and model interchanged. In the present situation there is one altimeter measurement between the two reference instruments and for simplicity the numerical model wave height estimate is taken at the location of the buoys. Because of the small number of available samples, we have also used altimeter measurements which are slightly above and below the connecting line (red dots in Fig. 8a). This resulted in ns=14 common data samples that could be used for the statistics.
Using this geometry allows for the estimation of the errors of all data sources, as well as the error correlations between the model wave heights (see Table 1). The calibration factors and their respective standard deviations were estimated with the direct and iterative method and are as follows.
The values in brackets were obtained with the iterative method. Significant differences are only found for the first scaling parameter. However, both methods provide consistent results if the error bars are taken into account. It is interesting to note that the scaling value for Sentinel-3A is closer to unity than the smaller value of about 0.8 found by the triple collocation method (Fig. 6b). This value was exceptional among the other buoys for which numbers above 1 were found for the most part. This could be an indication of a problem with station 62289, which also stands out in the stochastic errors shown in Fig. 7c.
The numbers obtained for the stochastic errors are as follows.
It can be seen that the estimates for the buoys are slightly negative, which is not meaningful for a variance. This can in fact happen for small sample sizes, since the estimators do not guarantee positive values. In this case it is helpful to look at the respective error bars, which are given as standard deviations. For a Gaussian-distributed variable the interval given by ± SD gives a 68 % confidence interval, i.e. more than 30 % of the cases are outside of this value range. This means that the estimated values for buoys are consistent with small positive error variances. The largest value is found for the Sentinel-3A altimeter with a relatively small error bar. This is consistent with the finding already made with the triple collocation method (see Fig. 7a). For the WAM model at the location of the 62289 station, the triple collocation method gave a similarly high value, but with almost 100 % error margin. The estimate obtained with the multi-collocation is significantly lower, but again with a large relative estimation error of about 100 %. Because of the smaller mean value, the latter estimates still point towards a smaller model error than indicated by the triple collocation method.
The covariances estimated for the WAM wave height errors at the two buoy locations correspond to a correlation value of 0.58. If we assume that the error autocorrelation function is Gaussian shaped, i.e.
with correlation length λC and spatial distance Δx, the above value results in λC=55 km.
Because of
knowledge about the variances and covariances also allows an estimate of the uncertainties in the gradient estimates. In this case an error standard deviation of 0.31 m was obtained for the difference of the WAM model wave heights at the two buoy locations.
5.2 2-D example
The geometry of the second example is depicted in Fig. 8b. This is an area in the northern part of the North Sea around 58∘ latitude between England and Norway. In this case an ascending Sentinel-3A track is passing through a group of three in situ wave observation platforms, which are shown in Figs. 1 and 2b. Here, we concentrate on two locations covered by the satellite, which appear as two clusters in Fig. 8b. The “North” group of satellite observations is shown in blue and the “South” group in red. Including the numerical model estimates at those locations, the situation is then as described by the last row in Table 1. One has 7 wave height estimates in total, and a 2-D plane approximation is used for the observed area. The multi-collocation method then allows an estimation of the errors of all components, as well as three covariances. As the buoy measurements can be assumed as independent, only two covariances are required in this example; this is the covariance between the model errors at the two locations and the same for the altimeter measurements. With this configuration the number of available data sets was ns=11.
The scaling values and their standard deviations obtained with the direct method are as follows.
Here, the values labelled “North” refer to the northern cluster of Sentinel-3A measurements (blue points in Fig. 8b) and the values labelled with “South” refer to the southern group of observations (red points in Fig. 8b). These estimates seem to be quite robust, because of the small error bars and the fact that the errors in both areas are very similar. The results also confirm the overall finding of the triple collocation analysis which indicated a wave height overestimation by the Sentinel-3A altimeter.
The respective values for the stochastic errors and their standard deviations with the same naming convention and obtained with the direct method are as follows:
Due to the significant estimation errors it is hard to tell which data source has the smallest errors. The obtained numbers are consistent with an error standard deviation of around 0.1 m for all data sets. The error estimates for the altimeter at the two locations agree very well and are also consistent with the values found with the triple collocation method (Fig. 7a). The difference in the error variances for the WAM model at the two locations appear to be quite big considering the distance of about 30 km. But again, the error bars show that there is a significant probability that the errors are actually in closer agreement. In principle, it would be possible to force the WAM error variances at the two locations to be the same, using a respective formulation of the linear system Eq. (12). However, looking at the spatial variations in the bathymetry in Fig. 1, this is hard to justify.
For the correlation, a value of 0.39 was found for the altimeter and a value close to 1 for the WAM model. This corresponds to a correlation length of about 30 km for the satellite data. It makes sense that the correlation length for the WAM model is longer in this case compared to the configuration discussed in the previous section, because the analysed area is in deeper water quite far offshore, and can therefore be assumed as more homogeneous with respect to model errors.
The examples show that the multi-collocation method is in fact applicable to real data source configurations. In particular, the matrix D in Eq. (12) is regular for the considered geometries, and estimates for error correlations can be obtained. It is also evident, of course, that the limited number of samples results in significant estimation errors. According to Eq. (19), the variance of the error variance estimation scales with 1∕ns, i.e. in order to reduce the error bars given in Eqs. (61) and (65) by a factor of 2, the number of samples has to be increased by a factor of 4.
The presented study provides an extension of the known triple collocation method, which can be useful in areas with stronger gradients, like coastal regions, where nearest-neighbour approximations maybe critical. The proposed method is very flexible in the way that various parameterisations can be used to describe the spatial variability of the measured quantities. In this study we considered only linear models, but this is not a restriction of the method, since more sophisticated functional forms (e.g. bilinear functions) can be easily integrated. Such higher-order approaches are certainly desirable for coastal areas with strong spatial variations; however, they require a larger number of data sources (see Eq. 9).
An approach was proposed to estimate the uncertainties in estimated calibration and stochastic errors, which is also useful in the context of the standard triple collocation method, which is a special case of the multi-collocation technique. The technique uses the covariance matrices of the input data and the number of samples as input, i.e. bootstrapping is not required. These uncertainty estimates are seen as very valuable, in particular in the context of new instruments for which only a limited data set is available for the assessment.
The proposed techniques were validated using Monte Carlo simulations with realistic background statistics. It was shown that the obtained error estimates and their respective uncertainties are in good agreement with the expected values, although a couple of approximations had to be used in the derivation.
The method was applied to a data set of in situ wave measurements, Sentinel-3A altimeter observations, and numerical wave model data. The number of available samples was relatively small and estimation errors had therefore to be taken into account. The usefulness of the derived error bars for the interpretation of the data could be demonstrated. For the analysed 16 months data set presented here, the estimation errors are significant, in particular if individual geographic locations are analysed. It would therefore be interesting to continue some parts of the analysis at a later stage of the Sentinel-3A mission, when a larger data set will be available. More robust results are obtained if the systematic and stochastic data set errors estimated for different in situ instrument locations are averaged. The results obtained for the North Sea indicate the smallest stochastic errors for the in situ measurements, as expected. The stochastic errors of the model and the altimeter seem comparable if averaged over all in situ locations. The analysis indicates that on average the altimeter is overestimating wave heights by about 10 % for above-mean wave conditions. Two examples of multi-collocations were analysed, which included a group of two and three in situ platforms. In both cases a Sentinel-3A track passed nearby, and model data were used in addition. The use of 1-D and 2-D parameterisations for the first and second example, respectively, resulted in estimates for the spatial decorrelation of model and altimeter errors.
The proposed method can be used for many other applications not discussed in this study. For example, it is straightforward to extend the analysis of error correlations to the time domain. The method can also be applied in situations where different instruments do not measure exactly the same quantity, but different components of a truth vector, for example HF radar providing 2-D current vectors and satellite SAR providing one current component (e.g. Hansen et al., 2011).
This study is supposed to make a contribution to the optimal use of the growing number of observations, in particular in coastal areas. For applications, like data assimilation, knowledge about the errors of different data sources is essential. Analysis of observation errors is also a critical component in the design and extension of observatories used for various applications. This subject will be of growing concern, for example, in the context of the European marine core service (CMEMS), where in situ data are required to optimise forecasts for all European seas.
The WAM model code can be found at http://mywave.github.io/WAM/ (WAM, 2018). The wind forcing data used for this study are available under https://cds.climate.copernicus.eu/cdsapp\#!/search?type=dataset (ERA5, 2018).
The authors declare that they have no conflict of interest.
This article is part of the special issue “Coastal modelling and uncertainties based on CMEMS products”. It is not associated with a conference.
This publication has received funding from the European Union's H2020 Programme for
Research, Technological Development and Demonstration under grant agreement
no. H2020-EO-2016-730030-CEASELESS. We thank Jean Bidlot from ECMWF for providing GTS
in situ data. BSH kindly gave access to waverider buoy measurements. We are grateful to
Luciana Fenoglio-Marc from the University of Bonn for providing Sentinel-3A altimeter
data. We thank Arno Behrens from HZG for assistance with the wave model.
The article processing charges for this open-access
publication were covered by a Research
Centre of the Helmholtz
Association.
Edited by: Agustín
Sánchez-Arcilla
Reviewed by: two anonymous referees
Alari, V., Staneva, J., Breivik, O., Bidlot, J.-R., Mogensen, K., and Janssen, P.: Surface wave effects on water temperature in the Baltic Sea: simulations with the coupled NEMO-WAM model, Ocean Dynam., 66, 917–930, https://doi.org/10.1007/s10236-016-0963-x, 2016. a
Anderson, G., Carse, F., Turton, J., and Saulter, A.: Quantification of bias of wave measurements from lightvessels, J. Oper. Oceanogr., 9, 93–102, https://doi.org/10.1080/1755876X.2016.1239242, 2016. a, b
Bidlot, J. and Holt, M.: Verification of operational global and regional wave forecasting systems against measurements from moored buoys, JCOMM Technical Report 30, WMO & IOC, Geneva, Switzerland, available at: http://hdl.handle.net/11329/101 (last access: 28 February 2019), 2006. a
Bidlot, J.-R., Holmes, D. J., Wittmann, P. A., Lalbeharry, R., and Chen, H. S.: Intercomparison of the performance of operational ocean wave forecasting systems with buoy data, Weather Forecast., 17, 287–310, https://doi.org/10.1175/1520-0434(2002)017<0287:IOTPOO>2.0.CO;2, 2002. a
Boukhanovsky, A., Lopatoukhin, L., and Soares, G.: Spectral wave climate of the North Sea, Appl. Ocean Res., 29, 146–154, https://doi.org/10.1016/j.apor.2007.08.004, 2007. a
Bouws, E. and Komen, G.: On the balance between growth and dissipation in an extreme depth-limited wind-sea in the southern North Sea, J. Phys. Oceanogr., 13, 1653–1658, https://doi.org/10.1175/1520-0485(1983)013<1653:OTBBGA>2.0.CO;2, 1983. a
Caires, S. and Sterl, A.: Validation of ocean wind and wave data using triple collocation, J. Geophys. Res.-Oceans, 108, 3098, https://doi.org/10.1029/2002JC001491, 2003. a, b, c, d, e, f, g, h
Cavaleri, L., Abdalla, S., Benetazzo, A., Bertotti, L., Bidlot, J.-R., Breivik, Ø., Carniel, S., Jensen, R. E., Portilla-Yandun, J., Rogers, W. E., Roland, A., Sanchez-Arcilla, A., Smith, J. M., Staneva, J., Toledo, Y., van Vledder, G. Ph., van der Westhuysen, A. J.: Wave modelling in coastal and inner seas, Progr. Oceanogr., 167, 164–233, https://doi.org/10.1016/j.pocean.2018.03.010, 2018. a
Chelton, D. B., Walsh, E. J., and MacArthur, J. L.: Pulse compression and sea level tracking in satellite altimetry, J. Atmos. Ocean. Technol., 6, 407–438, 1989. a
Chelton, D. B., Ries, J. C., Haines, B. J., Fu, L.-L., and Callahan, P. S.: Satellite altimetry, in: Satellite Altimetry and Earth Sciences, Vol. 69 of International Geophysics, 1–ii, Academic Press, 2001. a
ERA-5: wind forcing data, available at: https://cds.climate.copernicus.eu/cdsapp#!/search?type=dataset, last access: 30 November 2018.
Hansen, M. W., Collard, F., Dagestad, K.-F., Johannessen, J. A., Fabry, P., and Chapron, B.: Retrieval of sea surface range velocities from Envisat ASAR Doppler centroid measurements, IEEE Trans. Geosci. Remote Sens., 49, 3582–3592, 2011. a
Herbers, T., Hendrickson, E., and O'Reilly, W.: Propagation of swell across a wide continental shelf, J. Geophys. Res.-Oceans, 105, 19729–19737, https://doi.org/10.1029/2000JC900085, 2000. a
Hersbach, H. and Dee, D.: ERA5 reanalysis is in production, ECMWF newsletter, 147, 2016. a
Janssen, P. A. E. M., Abdalla, S., Hersbach, H., and Bidlot, J.-R.: Error Estimation of Buoy, Satellite, and Model Wave Height Data, J. Atmos. Ocean. Technol., 24, 1665–1677, https://doi.org/10.1175/JTECH2069.1, 2007. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Komen, G. J., Cavaleri, L., Donelan, M., Hasselmann, K., Hasselmann, S., and Janssen, P.: Dynamics and modelling of ocean waves, Cambridge university press, 1996. a
Le Roy, Y., Deschaux-Beaume, M., Mavrocordatos, C., Aguirre, M., and Heliere, F.: SRAL SAR radar altimeter for sentinel-3 mission, in: Geoscience and Remote Sensing Symposium, 2007, IGARSS 2007, IEEE International, 219–222, IEEE, 2007. a
McColl, K. A., Vogelzang, J., Konings, A. G., Entekhabi, D., Piles, M., and Stoffelen, A.: Extended triple collocation: Estimating errors and correlation coefficients with respect to an unknown target, Geophys. Res. Lett., 41, 6229–6236, https://doi.org/10.1002/2014GL061322, 2014. a
Reistad, M., Breivik, O., Haakenstad, H., Aarnes, O. J., Furevik, B. R., and Bidlot, J.-R.: A high-resolution hindcast of wind and waves for the North Sea, the Norwegian Sea, and the Barents Sea, J. Geophys. Res.-Oceans, 116, C05019, https://doi.org/10.1029/2010JC006402, 2011. a
Semedo, A., Vettor, R., Breivik, O., Sterl, A., Reistad, M., Soares, C. G., and Lima, D.: The wind sea and swell waves climate in the Nordic seas, Ocean Dynam., 65, 223–240, 2015. a, b, c
Stanev, E., Ziemer, F., Schulz-Stellenfleth, J., Seemann, J., Staneva, J., and Gurgel, K.-W.: Blending surface currents from HF radar observations and numerical modelling: Tidal hindcasts and forecasts, J. Atmos. Ocean. Technol., 32, 256–281, https://doi.org/10.1175/JTECH-D-13-00164.1, 2015. a
Staneva, J., Behrens, A., and Groll, N.: Recent advances in wave modelling for the North Sea and German Bight, Die Küste, 81, 233–254, 2014. a
Staneva, J., Alari, V., Breivik, O., Bidlot, J.-R., and Mogensen, K.: Effects of wave-induced forcing on a circulation model of the North Sea, Ocean Dynam., 67, 81–101, https://doi.org/10.1007/s10236-016-1009-0, 2017. a, b
Stoffelen, A.: Toward the true near-surface wind speed: Error modeling and calibration using triple collocation, J. Geophys. Res.-Oceans, 103, 7755–7766, https://doi.org/10.1029/97JC03180, 1998. a, b
Triantafyllopoulos, K.: On the central moments of the multidimensional Gaussian distribution, Math. Sci., 28, 125–128, 2003. a
Van Leeuwen, P. J.: Representation errors and retrievals in linear and nonlinear data assimilation, Q. J. Roy. Meteorol. Soc., 141, 1612–1623, 2015. a
Vogelzang, J. and Stoffelen, A.: Triple Collocation, Tech. Rep. NWPSAF-KN-TR-021, KNMI, Netherlands, 2012. a, b, c, d
Voorrips, A., Hersbach, H., Koek, F., Komen, G., Makin, V., and Onvlee, J.: Wave prediction and data assimilation at the North Sea, in: Elsevier Oceanography Series, Elsevier, 62, 463–471, https://doi.org/10.1016/S0422-9894(97)80056-6, 1997. a, b
WAM: WAM model code, available at: http://mywave.github.io/WAM/, last access: 30 November 2018.
Wiese, A., Staneva, J., Schulz-Stellenfleth, J., Behrens, A., Fenoglio-Marc, L., and Bidlot, J.-R.: Synergy of wind wave model simulations and satellite observations during extreme events, Ocean Sci., 14, 1503–1521, https://doi.org/10.5194/os-14-1503-2018, 2018. a, b
Woolf, D. K., Challenor, P., and Cotton, P.: Variability and predictability of the North Atlantic wave climate, J. Geophys. Res.-Oceans, 107, 3145, https://doi.org/10.1029/2001JC001124, 2002. a
Young, I., Babanin, A. V., and Zieger, S.: The decay rate of ocean swell observed by altimeter, J. Phys. Oceanogr., 43, 2322–2333, https://doi.org/10.1175/JPO-D-13-083.1, 2013. a