the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 24 Jan 2025
| 24 Jan 2025
Convolutional neural networks for sea surface data assimilation in operational ocean models: test case in the Gulf of Mexico
Alexandra Bozec
Eric P. Chassignet
Jose R. Miranda
Deep learning models have demonstrated remarkable success in fields such as language processing and computer vision, routinely employed for tasks like language translation, image classification, and anomaly detection. Recent advancements in ocean sciences, particularly in data assimilation (DA), suggest that machine learning can emulate dynamical models, replace traditional DA steps to expedite processes, or serve as hybrid surrogate models to enhance forecasts. However, these studies often rely on ocean models of intermediate complexity, which involve significant simplifications that present challenges when transitioning to full-scale operational ocean models. This work explores the application of convolutional neural networks (CNNs) in data assimilation within the context of the HYbrid Coordinate Ocean Model (HYCOM) in the Gulf of Mexico. The CNNs are trained to correct model errors from a 2-year, high-resolution () HYCOM dataset, assimilated using the Tendral Statistical Interpolation System (T-SIS). The CNNs are trained to replicate the increments generated by the T-SIS data assimilation package, aiming to correct model forecasts of sea surface temperature (SST) and sea surface height (SSH). The inputs to the CNNs include real satellite observations of SST from the Group for High Resolution Sea Surface Temperature (GHRSST), along-track altimeter SSH observations (ADT), the model background state (previous forecast), and the innovations (differences between observations and background). We assess the performance of the CNNs across five controlled experiments, designed to provide insights into their application in environments governed by full primitive equations, real observations, and complex topographies. The experiments focus on evaluating (1) the architecture and complexity of the CNNs, (2) the type and quantity of observations, (3) the type and number of assimilated fields, (4) the impact of training window size, and (5) the influence of coastal boundaries. Our findings reveal significant correlations between the chosen training window size – a factor not commonly examined – and the CNNs' ability to assimilate observations effectively. We also establish a clear link between the CNNs' architecture and complexity and their overall performance.
This research uses artificial intelligence to enhance ocean forecasting in the Gulf of Mexico. By using convolutional neural networks, the study improves predictions of sea temperatures and heights by integrating real satellite data with existing models. Through five comprehensive experiments, the team found that the amount of training data and the design of the neural networks significantly affect accuracy. These insights pave the way for faster, more reliable ocean models, benefiting environmental monitoring and maritime operations.
- Article
(7950 KB) - Full-text XML
- BibTeX
- EndNote





Assimilating diverse observations into operational ocean models presents significant challenges, primarily due to the computational demands and complexities associated with traditional methods like four-dimensional variational data assimilation (4DVar) or variations in the ensemble Kalman filter (EnKF). These methods, while robust, require substantial computational resources and time: 4DVar in the integration of the adjoint model and EnKF in the integration of the physician model itself. The data assimilation process can be particularly time-consuming when dealing with heterogeneous and high-volume datasets, which are becoming more common in oceanographic research. Machine learning methods, on the other hand, offer a promising alternative that could potentially accelerate this assimilation process.
Recent works in ocean sciences explore the feasibility and effectiveness of using techniques such as neural networks (NNs) to improve ocean models. For example, it has been explored how the entire variational data assimilation system could be substituted with machine-learning-based approaches (Geer, 2021; Boukabara et al., 2019; Dong et al., 2022). While this approach is still maturing, there is considerable interest in using machine learning to enhance existing data assimilation systems.
Additionally, machine learning methods have been applied to specific components of data assimilation systems in ocean models. For instance, it has been discussed how neural networks can be used for the fast emulation of forward models, which are crucial for the direct assimilation of satellite measurements in ocean models (Krasnopolsky, 2013). Furthermore, machine learning (ML) observation operators have been developed to improve the assimilation of surface observations such as sea surface temperature and ocean surface elevation (Guinehut et al., 2004).
This work investigates the use of convolutional neural networks (CNNs) to assimilate sea surface height and sea surface temperature observations with the HYbrid Coordinate Ocean Model (HYCOM). The CNNs are trained to correct the model error from a resolution 2-year-long data-assimilated HYCOM run with the Tendral Statistical Interpolation System (T-SIS) as the assimilation package. The performance of the CNNs is studied through five controlled experiments that provide insight into how to apply them in settings with full primitive equations, real observations, and complex topographies.
The experiments evaluate the architecture and complexity of the CNN, the type and number of observations, the type and number of assimilated fields, the response to the training window size, and the effects of the coastline. Our results show strong correlations between the window size selected to train the CNN, which is not commonly evaluated, and the ability of the CNN to assimilate the observations. Similarly, we found a clear relationship between the complexity of the chosen CNN and its overall performance.
Section 2 and 2.1 provide a small overview of HYCOM and the T-SIS assimilation system. Section 2.2 provides an introduction to CNNs and the U-net architecture. Section 3 describes the controlled experiments using CNNs, and Sect. 4 describes the results, the generalization tests performed, and the performance comparison with T-SIS. We end with conclusions and final remarks in Sect. 5.
The HYbrid Coordinate Ocean Model (HYCOM) is a state-of-the-art multi-layer ocean model (Bleck, 2002; Chassignet et al., 2003, 2007, 2009; Chin et al., 1999). A key feature of HYCOM is the use of a hybrid vertical coordinate. While the horizontal coordinates are typically Cartesian, the vertical coordinate need not be restricted to represent the vertical distance from a specified origin, the so-called “z coordinate”. In various parts of an ocean basin, the layer flow may be driven more strongly by different processes, which in turn gives preference to the use of a more suitable vertical coordinate. In the open stratified ocean, for example, the ocean flow typically follows along layers of constant potential density (isopycnals). For shallow coastal regions, terrain-following coordinates may be more suitable to characterize the flow subject to the kinematic constraints provided by the bathymetry. In the surface mixed layer or where the ocean is un-stratified, fixed pressure level coordinates may better represent the flow. The detailed choices for vertical coordinates for HYCOM are discussed in Chassignet et al. (2003).
The primitive equations of the HYCOM are detailed in Bleck (2002):
where v is the horizontal velocity vector, s is the vertical coordinate, ζ is the relative vorticity, f is the Coriolis parameter, k is the vertical unit vector, p is pressure, is the Montgomery potential, α is the potential specific volume, τ is the horizontal wind stress at the surface or drag at the ocean bottom, θ is one of two thermodynamic variables (either temperature or salinity), and ν is the eddy viscosity coefficient. The first, Eq. (1), is the momentum equation for the components of v, yielding two scalar equations. The second, Eq. (2), is the mass continuity equation. The third, Eq. (3), represents two scalar thermodynamic equations, one for each thermodynamic variable. Thus, there are a total of five equations that are being solved. A unique feature of HYCOM is that the vertical coordinate system can be modified at any given time step during model integration as flow conditions change. This is done through the use of a grid generator.
In addition to the equations above, HYCOM includes parameterizations that take into account other physical processes, such as vertical mixing (possibly due to turbulence), convection, and sea ice. HYCOM is a highly configurable model that can be run at a wide range of horizontal resolutions and vertical levels and can be driven using readily available lateral and boundary conditions (e.g., surface wind-forcing, tidal forcing, and bathymetry).
2.1 HYCOM data assimilation system
The HYCOM modeling system in this study utilizes the T-SIS data assimilation system (Srinivasan et al., 2022). In the earliest version of this system, T-SIS followed the classical Kalman filter approach for optimal interpolation. In this approach, it is assumed that the model forecast follows a Markov process, which means that the future state of the system depends only on its current state and not on any previous states (Davis, 2013). Observations can improve the estimate of the model state in a least squares sense, taking into account the modeled and observed error covariances as follows:
where x is the model state, f refers to the forecast operator (“the ocean model”), and the “a” superscript refers to the analysis after observations are assimilated. The matrix K is commonly known as the Kalman gain matrix, and it determines the relative weight given to the observations versus the forecast by taking into account model and observation error covariances. H is an observation operator that maps the modeled state variables to the observation variables. In the simplest scenario where the observations represent the same fields and have the same spatial and temporal resolution as the model, H is just the identity operator. In most cases, observations will sample only part of the model state; hence H will then interpolate the corresponding field(s) of the model state and perform any other transformation that may be needed. The Kalman gain is computed as
where Pf is the forecast model state error covariance matrix, and R is the observation error covariance matrix. When the observation errors are high (R is large), K gives low weight in the second term in Eq. (5), giving the forecast of the model more weight. In version 2.0 of T-SIS (Srinivasan et al., 2022), an alternative approach to calculate the Kalman gain is used.
The Kalman gain is computed by first defining the information matrix as , and then the information matrix is modeled by a Gaussian Markov random field (GMRF), which is a probabilistic model consisting of a set of random variables having a multivariate Gaussian distribution, with the Markov property that each variable is conditionally independent of all others given its immediate neighbors (Rue and Held, 2005). This property leads to a sparse precision (information) matrix L, making computations more efficient. Each element is conditionally specified based on a set of neighbors. Via spatial regression (Chin et al., 1999), the neighbors can be determined in a manner that can lead to a sparse matrix for L. This approximation of the inverse error covariance matrix results in a significant reduction in computational expense when used implicitly to solve Eq. (7). Speedups of an order of magnitude have been reported in Srinivasan et al. (2022).
Finally, after each assimilation step, there are further adjustments to the data in order to accommodate certain HYCOM constraints, such as model layer thickness adjustments, min–max thresholds, hydrostatic checks, and geostrophic balance. The data used in the assimilation have wide temporal and spatial availability.
2.2 Convolutional neural networks
Fully connected neural networks, or dense networks, have approximately parameters for every layer with m previous nodes and n current nodes. The number of parameters grows rapidly by incorporating additional intermediate layers, which are commonly needed to create complex models capable of approximating nonlinear systems. This makes dense networks impractical for training large-scale problems encountered in domains like computer vision, where each pixel in an image represents an input feature in the model. However, this limitation is overcome by the introduction of convolutional neural networks (CNNs).
CNNs are able to reduce the number of parameters in a neural network by sharing weights across different locations in the input data (LeCun et al., 1998). In CNNs, each neuron in a layer is connected only to a small region of the layer before it. This region is called the receptive field. This is from an inductive bias coming from the assumption that only nearby pixels in the images are likely to be related to each other, thus capturing local features in the input data like edges, textures, etc. CNNs are designed to process data with a grid-like topology (e.g., images).
Convolutional neural networks (CNNs) employ convolutions, a specialized type of linear operation, instead of general matrix multiplication in their layers (O'Shea and Nash, 2015). A convolution involves computing the output (feature map) by applying a filter (kernel) across the input, capturing local dependencies among input features. This operation is defined for sequences a and k as
where a is the input, k the kernel, and b the resulting feature map, demonstrating local connectivity. CNN architectures typically combine convolutional layers with pooling layers, which reduces the spatial dimensionality of feature maps, thereby decreasing the number of operations and enhancing computational efficiency (O'Shea and Nash, 2015).
U-nets, originally developed by Ronneberger et al. (2015) for biomedical image segmentation, are a type of convolutional neural network (CNN) characterized by a symmetric encoder–decoder architecture forming a U shape (Ronneberger et al., 2015). The encoder path, or contracting path, consists of repeated applications of convolutional layers followed by pooling layers, which progressively downsample the input. At each downsampling step, the number of channels is typically doubled, enabling the network to capture increasingly abstract features from the input data. The decoder path upsamples the feature maps using transposed convolutions or other upsampling techniques. This path reduces the number of channels by half at each step and at the end reconstructs the spatial dimensions of the original input. A main feature of U-nets is the inclusion of skip connections between corresponding layers in the encoder and decoder paths. These connections concatenate feature maps from the encoder directly to the decoder, allowing the network to retain high-resolution features that might otherwise be lost during downsampling. This design effectively preserves spatial information and enables precise localization, which is essential for tasks like segmentation.
Figure 1 illustrates a comparison between the classical convolutional neural network (CNN) architecture (top panel) and the U-net architecture (bottom panel). As previously described, U-nets incorporate three additional components that distinguish them from traditional CNNs.
-
Pooling layers. Represented by red blocks in the figure, these layers progressively reduce the spatial dimensions of the feature maps.
-
Upsampling convolutions. Shown as green blocks, these layers increase the spatial resolution of the feature maps.
-
Skip connections. Depicted by blue arrows, these connections concatenate feature maps from corresponding layers in the encoder and decoder paths.
In this example, both architectures receive an input image of size 256×256. The classical CNN employs convolutional layers with a uniform configuration of 64 filters each. In contrast, the U-net architecture uses a varying number of filters across its layers. Both architectures consist of 10 convolutional layers that try to maintain a comparable number of parameters and similar computational operations.
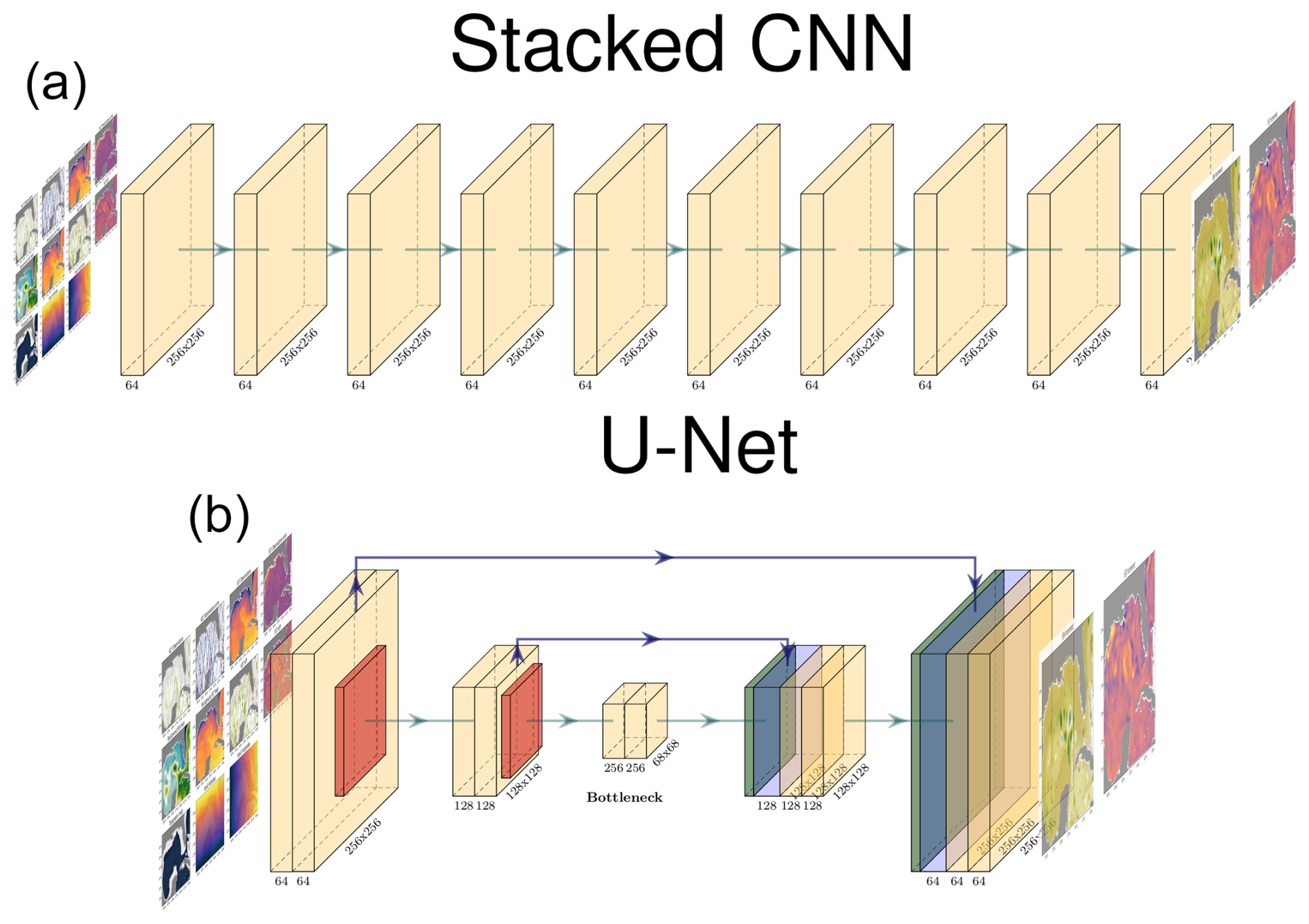
Figure 1Comparison of the classical CNN architecture (a) vs. the U-net architecture (b).
Over the past decade, U-net architectures have been extensively applied to a variety of geoscience problems due to their capability to learn hierarchical features and capture both local and global contexts. Variants of U-net, such as the Attention U-net (Oktay et al., 2018) and the Small Attention U-net (SmaAt U-net) (Roy et al., 2018), have been developed to enhance feature extraction and improve performance in complex geoscientific tasks. These variants introduce mechanisms like attention gates and efficient channel interdependencies, allowing models to focus on relevant features while reducing computational requirements. Some notable applications of the use of U-nets in geoscience include the following.
-
Remote sensing and Earth observation. U-nets have been extensively used for semantic segmentation and classification of satellite imagery, including land cover mapping (Russwurm and Korner, 2018), building and road extraction (Maggiori et al., 2017; Demir et al., 2018), and change detection (Daudt et al., 2018).
-
Meteorology and climate science. U-net architectures have been employed for precipitation nowcasting using radar data (Agrawal et al., 2019).
-
Hydrology and flood mapping. U-nets have been applied to flood detection and mapping from satellite images (Pech-May et al., 2024) and mountain ice segmentation (Tian et al., 2022).
-
Oceanography. U-net architectures have been utilized in oceanography for bathymetry estimation from optical imagery (Nicolas et al., 2023) and ocean eddy detection and classification (Lguensat et al., 2018).
-
Data assimilation and ocean modeling. Beauchamp et al. (2022) introduced multimodal 4DVarNets, where U-net-based architectures obtain similar results to 4DVarNets for the reconstruction of sea surface dynamics by leveraging synergies between sea surface temperature (SST) and sea surface height (SSH) observations. Their work demonstrates the capability of deep learning models to assimilate multiple data modalities and reconstruct ocean surface variables with high accuracy.
The versatility of U-net architectures in geoscientific applications makes them a suitable choice for data assimilation in ocean modeling, given their ability to capture spatial dependencies and manage multiscale features. This capability aligns well with the demands of integrating observational data into ocean models, motivating our choice to adopt this architecture.
In this section, we explore the use of convolutional neural networks (CNNs) as a data assimilation technique for ocean models. We assess the performance of multiple CNN models across five experimental setups. These models assimilate data from sea surface temperature (SST) and sea surface height (SSH) observations. Their performance is compared with results obtained through the optimal interpolation method implemented in T-SIS. The experiments are conducted in the Gulf of Mexico, covering a domain from 18.09 to 31.96° latitude and −98.0 to −77.04° longitude, as depicted in Fig. 2.
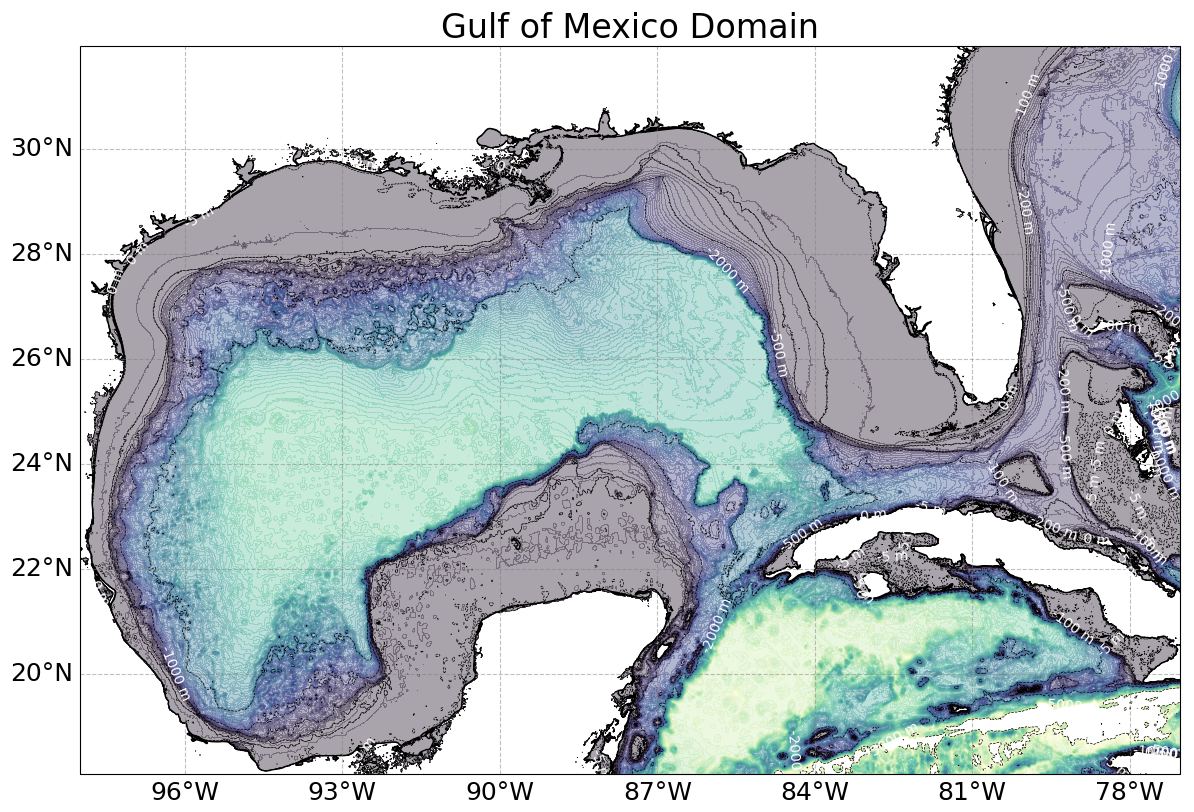
Figure 2This map illustrates the geographic limits within the Gulf of Mexico used for our experiments.
3.1 Data
The ocean model used is the HYbrid Coordinate Ocean Model (HYCOM) with a spatial resolution of . The GOMb0.04 domain is set up with the high-resolution 1 km bathymetry of the Gulf of Mexico (Panagiotis, 2014) over a domain going from 18 to 32° N in latitude and from 98 to 77° E in longitude. With 41 hybrid layers in the vertical, the latest version of HYCOM (2.3.01: https://github.com/HYCOM/HYCOM-src, last access: 1 June 2024) is forced at the surface with the NCEP CFSR/CFSv2 hourly atmospheric forcing. The lateral open boundaries are relaxed to daily means of the global HYCOM GOFS3.1 reanalysis (https://www.hycom.org/dataserver/gofs-3pt1/reanalysis, last access: 1 June 2024). The initial conditions are taken from a 20-year reanalysis created with the same configuration.
The T-SIS package, detailed in Sect. 2.1, is utilized with HYCOM for producing the increments, which are used to correct the model state and generate the analysis. To optimize the system's performance for the HYCOM Lagrangian vertical coordinate system, subsurface profile observations are first layerized (re-mapped onto the model's hybrid isopycnic–sigma–z vertical coordinate system) prior to assimilation. The analysis procedure then updates each layer separately in a vertically decoupled manner. A layerized version of the Cooper and Haines (1996) procedure is used to adjust model layer thicknesses in the isopycnic-coordinate interior in response to SSH anomaly innovations (differences between observed values and the background state). In the data assimilation field, innovations refer to the differences between the observed values and the model's background (prior) estimates of those values, expressed in the observation's frame of reference. Before calculating SSH innovations the mean dynamic topography (MDT) is added to the altimetry observations. A MDT derived from a 20-year free run of the GOMb0.04 configuration is used for converting a sea level anomaly (SLA) to SSH. The multiscale sequential assimilation scheme based on a simplified ensemble Kalman filter (Evensen, 2003; Oke et al., 2002) is used to combine the observations and the model to produce best estimates of the ocean state at analysis time.
To train the CNN models, we use real satellite observations of sea surface temperature (SST) from the Group for High Resolution Sea Surface Temperature (GHRSST) dataset and along-track altimeter sea surface height (SSH) observations (ADT). The model background state, representing the previous forecast from HYCOM, is also used as input. Additionally, the increments are also used as input, which are the differences between the observations and the model background state. The CNNs are trained to replicate the increments generated by the T-SIS data assimilation package. In summary, the CNNs learn to map the background state, observations, and innovations to the increments, effectively emulating the data assimilation step performed by T-SIS.
It is important to note that while the SST observations from GHRSST provide near-complete spatial coverage, the SSH observations from along-track altimeter data are sparse and irregularly distributed. The DA schemes are able to handle such sparse datasets and propagate the observational information across the model domain. This is achieved through statistical interpolation and the physical dynamics represented in the model by the T-SIS system, which together allow us to estimate the ocean state in unobserved areas based on the available observations.
This assimilative ocean model configuration is initially run for 2 years (2009 and 2010), generating a total of 730 daily outputs. These outputs are used to train and validate the proposed CNN models. Each day's increment fields of SSH and SST, , the background state , and the observations yt are employed to train the CNN models.
In Earth sciences, particularly in ocean modeling, data leakage is a significant concern due to the strong temporal autocorrelation in the data. The state of the ocean does not change dramatically over short periods, which means that random splitting of data can lead to leakage where the model learns from future information. To mitigate this, we employed a chronological data splitting strategy. From the 730 daily examples the first 80 % is used for training, 10 % for validation, and the last 10 % for testing, ranging from 19 October to 31 December 2010. This method ensures that the model is trained on past data and evaluated on future data, reducing the risk of information from the test set influencing the training process. However, we recognize that the proximity of the training and test sets may still allow for some data leakage due to the ocean's slow-changing nature.
To further assess the model's ability to generalize and to address potential data leakage, we tested the model on datasets from the years 2002 and 2006. These years were selected because they exhibit different dynamical states of the Gulf of Mexico (GoM), with the loop current mostly in retracted and extended phases, respectively. By evaluating the model on data that are entirely separate from the training and validation sets and representing different oceanographic conditions, we reduce the likelihood that the model's performance is artificially inflated due to data leakage.
The model maintained strong performance in these additional datasets, with RMSE values comparable to those on the original test set as described in the “Generalization tests” section.
3.2 Preprocessing
Prior to training the convolutional neural network (CNN) models, we performed several preprocessing steps to ensure that the input data were appropriately scaled and formatted. First, to address the issue of differing value ranges among the input variables, we normalized each field individually. This normalization involved adjusting each input field – such as sea surface temperature (SST) observations and sea surface height (SSH) observations – to have a mean of zero and a standard deviation of 1. Normalization is an important step in machine learning, as it ensures that all input features contribute equally during training, preventing variables with larger magnitudes from disproportionately influencing the model's learning process. By standardizing the inputs, we facilitated a more stable and efficient optimization during model training.
The parameters used for normalization, specifically the mean and standard deviation for each input field, were calculated using the data from the full training period, encompassing the years 2009 and 2010. These calculated parameters were then applied to the validation and test datasets, as well as to the additionally tested years 2002 and 2006.
After the CNN models generated the predicted increments, we applied an inverse transformation using the previously calculated mean and standard deviation to denormalize the outputs. This denormalization step converted the increments back to their original units – such as degrees Celsius for SST or meters for SSH – making them compatible with the model forecast corrections. By restoring the original scale of the data, we ensured that the increments could be directly applied to the HYCOM outputs.
We addressed the irregular distribution and missing values of the along-track altimeter SSH data by mapping these observations onto the model grid and filling the missing data points with zeros. Representing the absence of observations with zeros allowed the CNN models to process the SSH data as continuous fields, where zeros explicitly indicated locations without observational data. The response of the CNN to missing values represented as zeros is of interest to us and was part of the experiments.
The loss function was computed only over ocean grid points. This ensured that the network focused solely on learning the ocean dynamics and was not penalized for predictions over land. After the models were trained and used for predictions, we applied the land mask to set the values at land grid points to not a number (NaN). This step ensured that the output fields contained valid data only over ocean areas, aligning with the physical reality that oceanographic variables are undefined over land.
Additionally, since T-SIS does not provide SSH increments for shallow areas (depths less than 200 m), we included a mask indicating areas with depths greater than 200 m. This depth mask was provided as an additional input channel to help the CNN learn this restriction and avoid predicting increments in shallow regions where T-SIS does not apply corrections.
The input tensors to the CNN models are four-dimensional arrays with the following dimensions: batch size, height, width, and channels. The numbers for height, width, and channels vary depending on the experiment. All input tensors are of type float32 (single-precision floating-point type).
3.3 Experiments
The CNNs' performance is assessed through five controlled experiments designed to test the expected behavior in practical operational settings with full primitive equations, real observations, and complex topographies. These experiments investigate the CNNs' response relative to the size of the spatial windows used for model training, the complexity of the CNN architecture, the number and types of ocean fields used as input and output fields, and the allowed ocean percentage in the training examples. In the experiment analyzing network complexity, we evaluated different network complexities by comparing simple CNN architectures with varying depths (2, 4, 8, and 16 layers) to the U-net architecture. This experiment aims to assess the impact of network depth on model performance. All subsequent experiments utilize the U-net architecture exclusively to explore the effects of window size, input configurations, ocean percentage, etc.
It is important to note that our experiments are not twin experiments. In twin experiments, synthetic observations are generated from a model run (considered the “truth”) and are then assimilated back into the model to assess the data assimilation system under controlled conditions. In our study, real observational data are used for both training and testing our CNN models. The T-SIS data assimilation system generates increments based on these real observations, and our CNN models are trained to replicate these increments. By using actual observations from GHRSST for SST and along-track altimeter data for SSH, our experiments reflect a more realistic scenario where the CNN models learn from real-world data, capturing the complexities and uncertainties inherent in operational ocean modeling.
Figure 3 shows an example of all the possible inputs and outputs tested in the experiments. The first row of the inputs displays the sparse SSH observations and the associated error. The second row displays the model background state and the difference with respect to the observation. The third row shows additional inputs for the CNN that can improve the prediction (200 m mask and normalized latitude and longitudes). The final row shows the SSH and SST increments produced by T-SIS and learned by the CNN model. Despite the sparsity of the SSH observations, the CNN models produce complete increment fields by propagating the information throughout the domain.
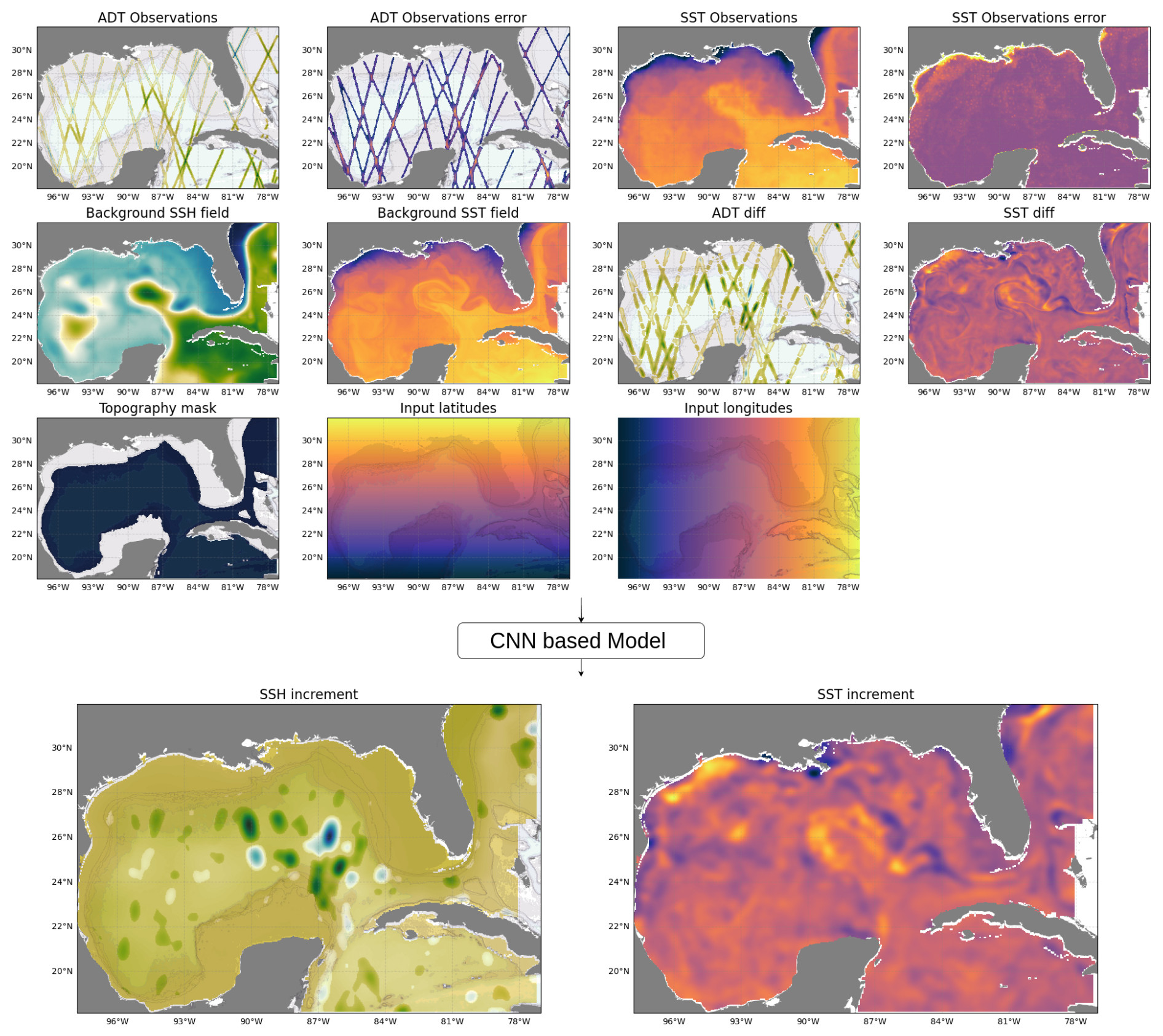
Figure 3Example of all the possible inputs and outputs tested in the experiments. The first row of the inputs displays the sparse SSH observations and the associated error. The second row displays the model background state and the difference with respect to the observation. The third row shows additional inputs for the CNN that can improve the prediction (200 m mask and normalized latitude and longitudes). The final row shows the SSH and SST increments produced by T-SIS and learned by the CNN model. Despite the sparsity of the SSH observations, the CNN models produce complete increment fields by propagating the information throughout the domain.
3.3.1 Window size
The first experiment examines the CNNs' performance relative to the size of spatial windows used as input. Training a CNN within a fixed domain does not guarantee effective generalization to other domains. Despite the translational invariance of convolutional layers, models may develop biases based on the specific features, such as land–sea boundaries, within the training domain, making it challenging to generalize to domains with different coastlines and ocean dynamics. Conversely, using the entire domain as the training set provides only one training example per day. Training with smaller windows increases the number of examples, potentially enhancing generalization but possibly at the expense of losing context provided by the larger domain.
Training a model with the full domain provides just one training example per day. When training with smaller window sizes, the total number of training examples is determined by how many sub-windows can fit within our domain. For each dimension, the total number of sub-windows that can be selected is given by
where Ds represents the dimension size, and Ws denotes the window size. For instance, if the domain size is 10×10 and the window size is 5×5, we can fit a total of 6 windows in each dimension or a total of 36 different examples. In our experiments, when training the networks with a window size smaller than the full domain, 10 random windows are selected for a given day, and each epoch is completed after 1000 of these randomly selected windows are generated. The random images change between batches and epochs. The experiment compares performance across four window sizes: the entire domain (384×520 pixels) and smaller windows of 160×160, 120×120, and 80×80 pixels (Fig. 4).

Figure 4Examples of randomly selected training windows at various sizes: 385×520 pixels for the full domain and 160×160, 120×120, and 80×80 pixels.
To assess the impact of spatial coordinates on model performance, we conducted additional experiments by including normalized latitude and longitude fields as input channels to the network. The latitude and longitude values were scaled between 0 and 1 to align with the normalization of other input features.
3.3.2 CNN complexity
The second experiment evaluates the performance of the CNNs for data assimilation concerning the complexity of the CNN architecture. Five different models are evaluated using two CNN architectures. The first four models follow a simple CNN architecture, which we refer to as SimpleCNN. Models from this architecture are built by stacking convolutional layers with an increasing number of filters. Each hidden convolutional layer employs a rectified linear unit (ReLU) activation function, and the last two convolutional layers contain a single filter and a linear activation function. The four models using this architecture vary in the number of hidden convolutional layers with 2, 4, 8, and 16 layers. The second architecture tested follows the encoder–decoder architecture with skip connections from the U-net (Ronneberger et al., 2015). For this architecture, one model with 3 levels and 18 CNN layers is evaluated. Each convolutional layer in the U-net architecture is followed by a ReLU activation function and a batch normalization layer, except for the final output layer. The inclusion of batch normalization helps stabilize and accelerate training and provides regularization benefits by reducing the internal covariate shift. Figure 5 presents detailed information on this model, where all CNN layers except the last one use the ReLU activation function.
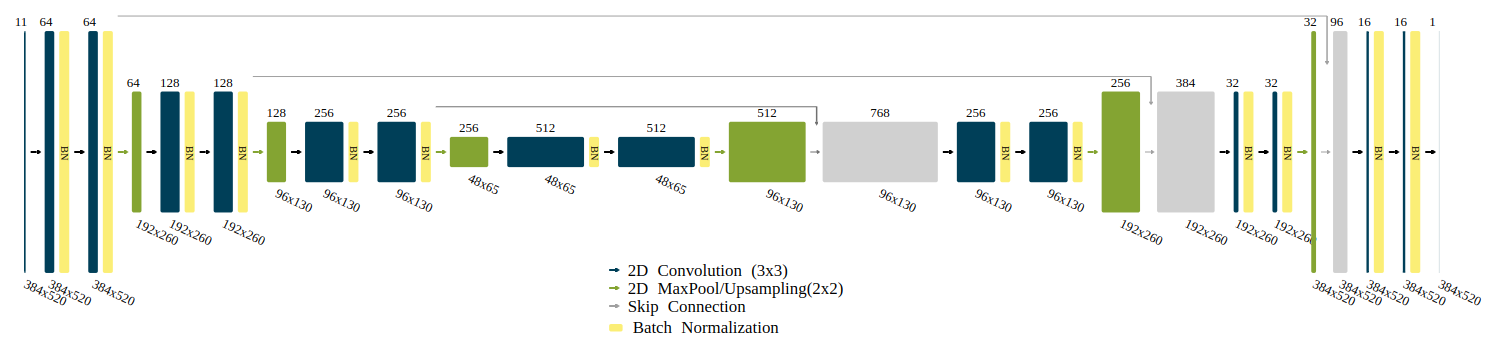
Table 1 shows the names, number of hidden layers, and number of filters used at each hidden layer for the five model architectures tested.
Table 1Summary of the number of hidden layers and filters tested in each of the proposed CNN architectures.

3.3.3 Input types
This experiment investigates the use of multiple ocean fields as inputs in our models. Traditional methods, which approximate the model's error covariance matrix, face scalability challenges when multiple fields are integrated into the assimilation process, significantly increasing the matrix size. By varying the input types, including SST, SSH, and their respective observation errors we evaluate the potential of a unified deep learning model to assimilate diverse data sources effectively.
3.3.4 Outputs
This experiment evaluates the network's performance concerning the type and number of output fields. As in the previous experiment, having a single model that can assimilate observations into multiple fields is desired. The two fields considered in this experiment are SSH and SST, tested individually and jointly. The primary objective is to investigate whether a moderately complex CNN model can assimilate observations from multiple fields as effectively as from a single field.
3.3.5 Percentage of ocean
Given that CNNs were originally designed for image processing, they typically do not account for non-valid pixels like land areas. This experiment varies the minimum ocean area required in the training windows, testing thresholds of 0 %, 30 %, 60 %, and 90 %. For the 0 % scenario, there are no restrictions imposed on the ocean coverage within the training windows, meaning these windows could entirely encompass land areas. Conversely, in the 90 % scenario, any training windows containing less than 90 % ocean coverage are excluded. The window size for this experiment is fixed at 160×160 pixels.
Table 2 summarizes the parameters and their respective values tested in our experiments. Each parameter was varied independently to assess its impact on the performance of the CNN models in assimilating oceanographic data. By exploring different combinations of window sizes, CNN complexities, ocean percentages, inputs, and outputs, we aimed to gain comprehensive insights into the behavior and capabilities of the models under various conditions. Each tested model is trained five times to gather statistics on the training's consistency and allow a more accurate comparison between the models' performances. A total of 75 CNN models are evaluated in these experiments.

3.4 Training hyperparameters
All models are trained using the Adam optimizer (Kingma and Ba, 2014) with a learning rate of 10−3. The loss function used is the mean square error (MSE), evaluated between the increment provided by the CNN and the one generated by the T-SIS model. The MSE loss is only evaluated in the grid cells where there is ocean, and the CNN models' outputs are always masked by land areas, which are irrelevant for data assimilation in the ocean. We used a batch size of 32 to train the models. All training ended when the error in the loss function of the validation set had not decreased for 20 epochs; the model with the lowest validation loss is used for the statistics.
We conducted initial experiments incorporating a dropout rate of 20 % after the convolutional layers. However, we observed that the networks with dropout exhibited lower performance compared to those without dropout. This could be attributed to the size of our training dataset, which may not be large enough for dropout to be effective. Consequently, we opted not to include dropout in our final models to maintain optimal performance.
Regarding optimizer selection, we used the standard Adam optimizer with default parameters in our experiments. We acknowledge that the AdamW optimizer, which includes decoupled weight decay for L2 regularization, could potentially enhance generalization by applying a stronger weight penalization. We plan to explore the use of AdamW with increased weight decay in future work to assess its impact on model performance.
In this section we describe and analyze the results from the proposed experiments to use CNN for data assimilation in ocean models. For each combination of parameters five models are trained, and the error bar plots show the mean (orange line), median (green triangle), and standard deviation of the models. The statistics are obtained from the test set, with dates from 19 October to 31 December 2010. For all the experiments the y axis is the RMSE in meters (already denormalized) of the difference between the increment provided by T-SIS and the one provided by the CNN.
4.1 Window size
Figure 6 shows a performance comparison with respect to the window size used to train the networks. In this experiment, all other parameters remain fixed, with U-net serving as the default architecture. The SSH increment is used as the target output, and the SSH background state and satellite altimeter observations yt are used as inputs. Furthermore, a mask delimiting areas in the GoM deeper than 200 m is included as input because T-SIS does not generate any SSH increment for shallow areas. To enable the CNN to learn this restriction, we provided this mask as an additional input channel.
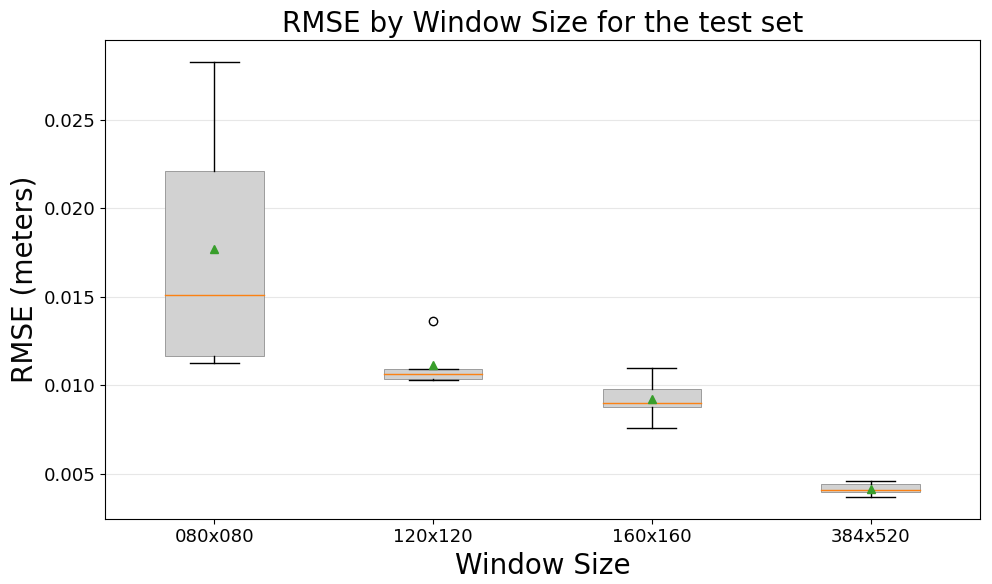
Figure 6RMSE comparison between CNN models and the T-SIS method across different window sizes on the test dataset.
The experiment reveals a clear relationship between the model's performance and the size of the window used for training. Larger windows yield better performance, and using the entire domain for training achieves the best results. These results indicate that the CNN is benefiting from the context of the full domain and is not being affected by the reduced number of training examples that this configuration generates.
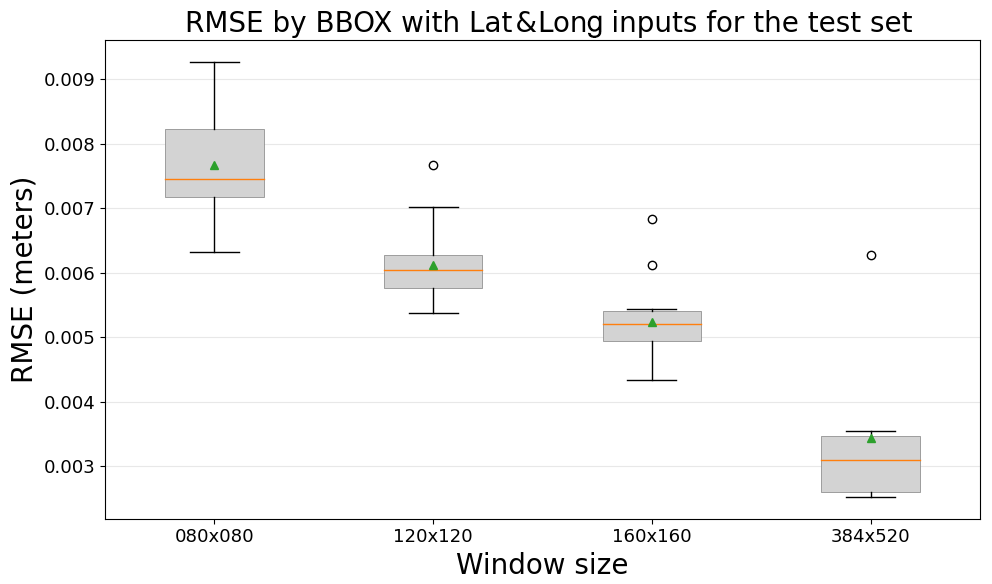
Figure 7RMSE comparison between CNN models and the T-SIS method across different window sizes on the test dataset, with the inclusion of latitude and longitude as additional inputs.
The inclusion of latitude and longitude as additional inputs does reduce the RMSE of the models, especially those that are trained with smaller windows, as shown in Fig. 7. This indicates that the additional input layers provide useful spatial information to the models. The tendency still remains the same: larger windows yield better performance, and the best results are obtained when the entire domain is used for training.
4.2 CNN complexity
Figure 8 presents the results of the comparison of the CNN architecture and complexity. As before, all other parameters remain fixed. In this case, we used the full domain to train the models, with the SSH increment used as the target output and SSH background state, shallow water mask, and satellite altimeter observations serving as input.
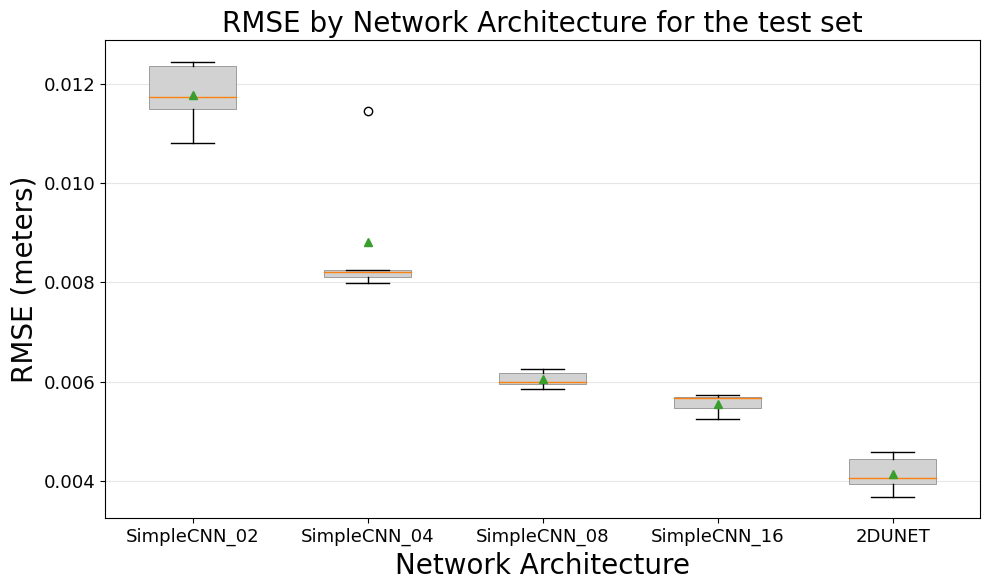
Figure 8RMSE comparison between CNN models and the T-SIS method across different architectures on the test dataset.
The results illustrate that, for the problem of data assimilation in ocean models mimicking the optimal interpolation method, the CNNs' performance improves with increased complexity in their architecture. Two key observations include the exponential decay observed in the RMSE of the loss function relative to the complexity for the SimpleCNN architectures (as the number of hidden layers increases) and how the more advanced U-net architecture, incorporating batch normalization, skip connections, and an encoder–decoder design, yields the best performance. It is worth noting from this experiment that although there is a clear relationship between the complexity of the CNNs' architectures and the performance obtained, the difference between them is not too big. The SimpleCNN architecture with only four hidden CNN layers already approximates the T-SIS data assimilation package with an RMSE of just 8 mm.
4.3 Ocean percentage
Figure 9 presents the results of the experiment that compares the percentage of ocean required in the training windows. Recall that the goal of this experiment is to investigate how grid cells with land areas can affect the training of the CNNs – which is not common in computer vision problems. For this experiment, the window size is fixed at 160×160, the network architecture is the U-net, the SSH increment is used as the target output, and the SSH background state and satellite altimeter observations are used as inputs.
Interestingly, we do not identify a clear trend between the performance of the CNNs and the percentage of ocean specified in the training examples. These results suggest that CNNs are not significantly affected by land grid cells when addressing the problem of data assimilation in ocean models.
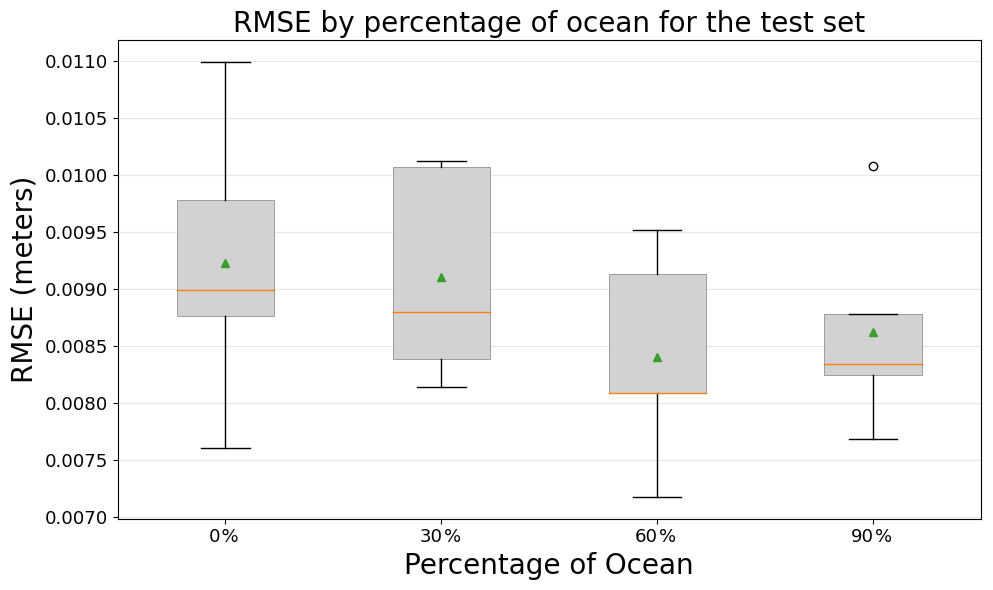
Figure 9RMSE comparison between CNN models and the T-SIS method across different percentages of ocean areas in training examples on the test dataset.
4.4 Inputs
Figure 10 presents the results of including additional observations as input to the models. For this experiment, the rest of the parameters are as follows: U-net is used as the network architecture, the entire domain is used to train the models, and the SSH increment serves as the target output. The three tested input observations are the satellite altimeter tracks (SSH), the altimeter tracks combined with SSH and their corresponding observational errors (SSH, SSH-ERR, SST, SST-ERR), and the altimeter tracks combined with SST but without the error information (SSH–SST).
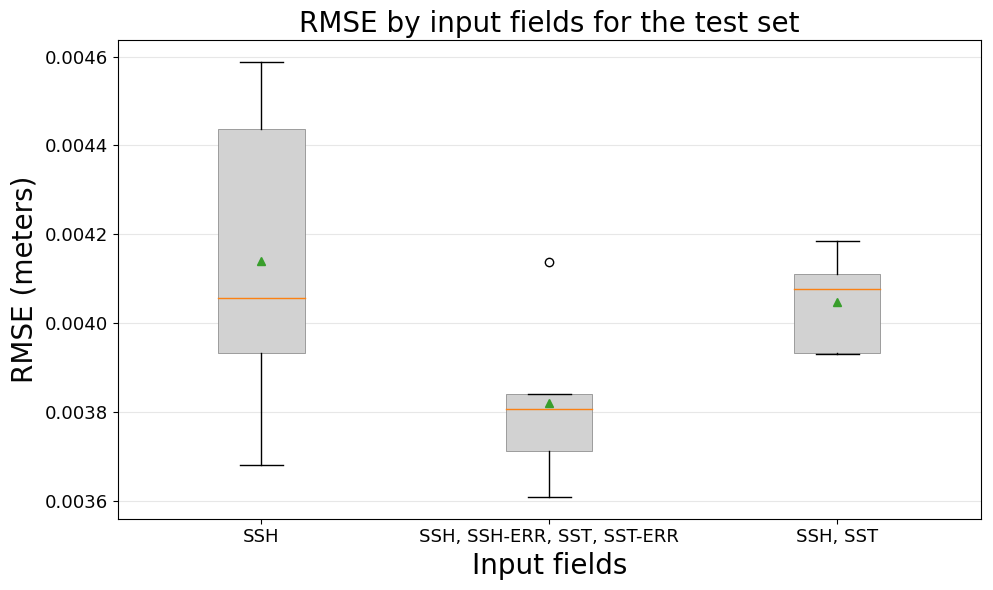
This experiment reveals how the CNN models might benefit from additional observations as inputs. The performance improves when the error in the observations is included as an input (as an extra channel in the input layer), and the variance of the trained models improves when including SST observation as an input variable. It is expected that the performance improves by including the observational error because T-SIS uses it to compute the increment – the error covariance matrix of the observations, in Eq. (6), contains this information. However, it is noteworthy to show that including additional SST observations does not affect the model's performance even though we know that SST is not used by T-SIS to generate the SSH increment.
4.5 Outputs
Finally, Fig. 11 presents the results of testing CNNs to simultaneously generate multiple data assimilation increments, in this case, SSH and SST. The rest of the parameters are as follows: U-net is used as the network architecture, the entire domain is used to train the models, and the SSH increment serves as the target output. The three output increments tested are the satellite altimeter tracks (SSH), sea surface temperature (SST), and both together (SSH–SST).
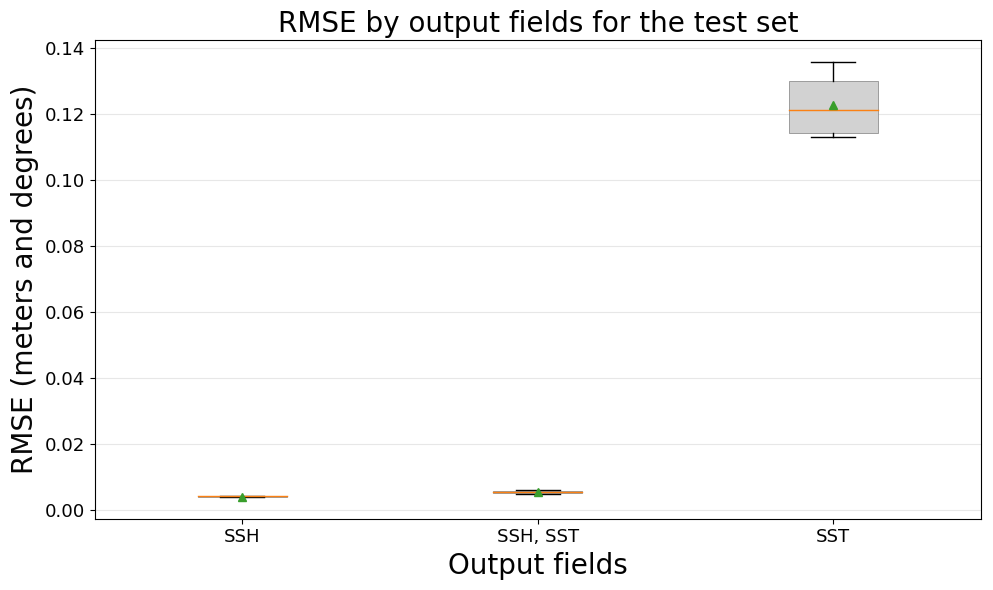
Figure 11RMSE comparison of CNN models by the number and types of output fields, evaluated on the test dataset.
For this final experiment, it is important to note that the y axis is in meters for the first two models, SSH and SSH–SST, but it is in degrees for the last case of SST. The key takeaway from this experiment is that the performance in predicting the SSH increment is not affected when the model is tasked with generating both increments (SSH and SST) simultaneously. This indicates the ability of the CNNs to manage multiple outputs without a significant drop in performance for individual tasks.
4.6 Generalization tests
Following the series of experiments in the previous section, which provide insights into the performance of CNNs in an operational ocean model setting with data assimilation, the best model was selected based on optimal parameters. This model utilized the U-Net architecture; was trained using the entire domain of the Gulf of Mexico (GoM) for training examples; and incorporated the SSH observations, the SSH observation errors, the SSH background state, and a binary mask indicating depths greater than 200 m as inputs. The desired output was the increment of SSH, essentially the corrections to be made to this field in the model on a daily basis.
The ability to generate complete assimilated fields from sparse observations is a fundamental aspect of the data assimilation process. By taking advantage of the spatial covariance structures and dynamical relationships within the ocean model, the DA scheme can infer the state of the ocean in regions without direct observations. Our CNN models are trained to learn this mapping from inputs (sparse observations and background state) to outputs (complete increments), effectively capturing the essence of the DA process even though the sparse observations are filled with zeros.
Figure 12 illustrates a comparison between the SSH increment as predicted by T-SIS and the increment predicted by the CNN model for a specific day, 27 October 2010, from the test dataset. Generally, the overall predictions are similar, with the RMSE across the entire domain in this example being 3.2 mm. This day was randomly selected to provide a representative example of the model's performance in a typical scenario.
However, the figure also reveals some discrepancies, primarily at the peripheries of areas where there is an increment. This could potentially be attributed to a hard threshold within T-SIS that does not provide any increments beyond a certain distance from the observation. An expected pattern from Fig. 12 is that the corrections to the model are made predominantly close to the locations of the satellite tracks.
Figure 13 depicts RMSE for the entire test set, ranging from 19 October to 31 December 2010, as well as the initial days of the year used for training. The mean RMSE for the entire test set is 3.72 mm, while for the days used for training it is 3.51 mm. This suggests that the CNN model is effectively generalizing to unseen examples. However, two points need to be considered in this analysis:
-
The Gulf of Mexico's dynamics do not change rapidly over time. Hence, the dynamical state of the GoM for the test set might be quite similar to the state used for training the model.
-
There is a slight discrepancy in the mean RMSE between the training and test sets, indicating that a more comprehensive experiment is necessary to understand how effectively the model generalizes to unseen examples where the GoM's dynamical state differs from that in the training set.
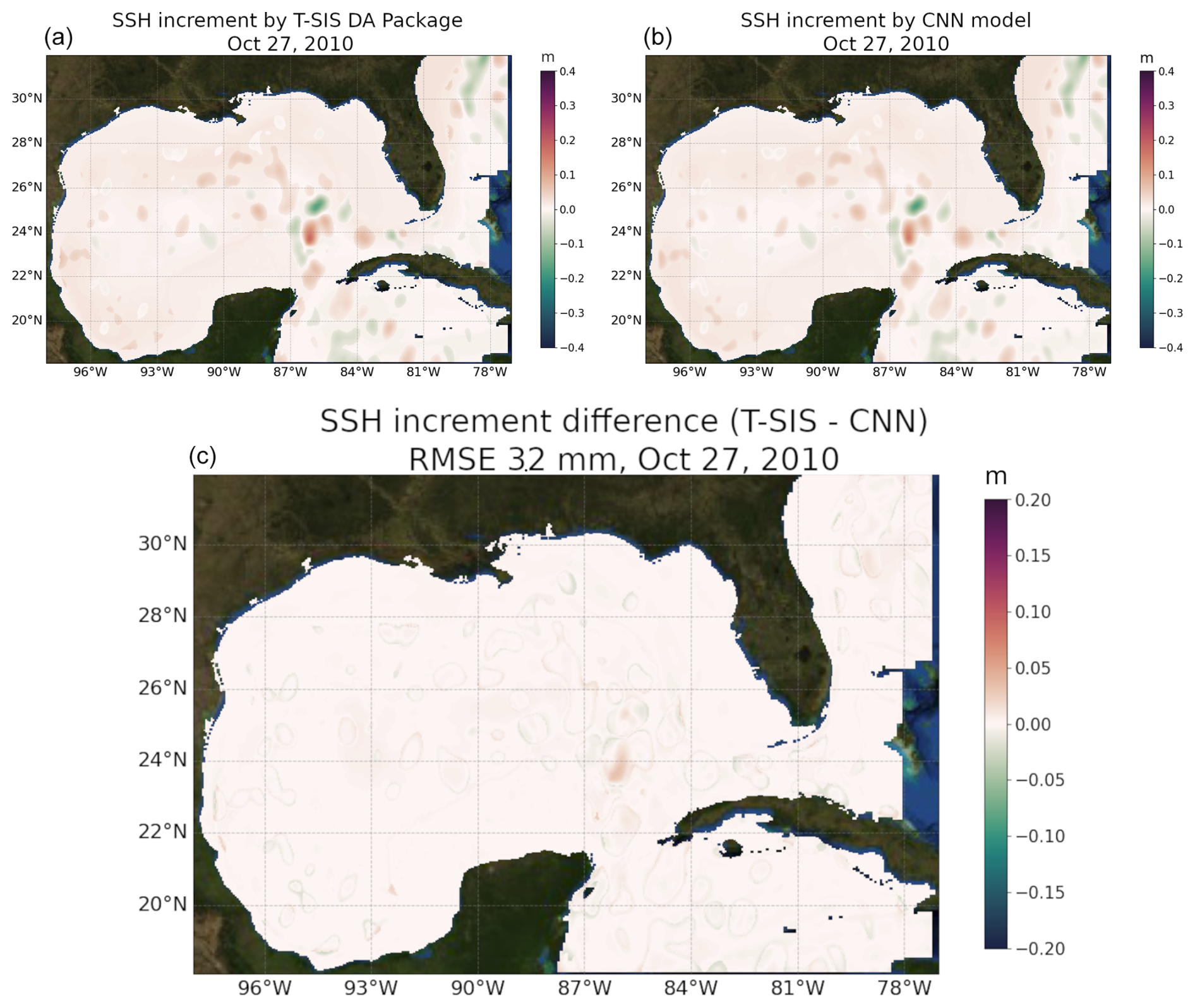
Figure 12Comparison of predicted model error (increment) for sea surface height from T-SIS in (a) and from the proposed CNN model in (b). Panel (c) displays the root mean square error (RMSE) between both predictions.
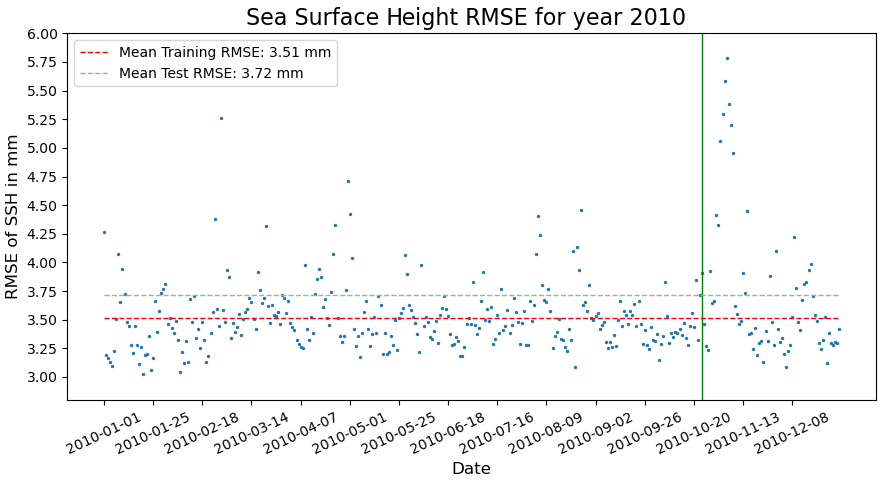
Figure 13RMSE of the proposed CNN model for the year 2010. The vertical green line indicates the date where the test dataset starts. The two dashed lines indicate the RMSE of the training and test sets. Date format is year-month-day.
To scrutinize the model's ability to generalize across different dynamical states of the GoM, 2 contrasting years were chosen based on the states of the loop current (LC), the key driver of ocean dynamics in the GoM. Notably, it is challenging to confidently predict how a trained model will perform on unseen data. In experiments that use synthetic data, it is simpler to identify examples that fall outside of the training distribution, but in this scenario, the process is not as straightforward. The assumption is that the CNN model will learn to assimilate observations in the GoM comparable to the optimal interpolation method in T-SIS and will generalize correctly to data from different years, regardless of the GoM's dynamical state.
The years 2002 and 2006 were selected for this test. In 2002, the LC is primarily in a contracted state, while in 2006, it is predominantly in an extended state, with some eddies being shed throughout the year. New assimilated runs of HYCOM and T-SIS were created for these 2 years as described earlier, featuring a spatial resolution and using NCEP CFSR/CFSv2 as the atmospheric forcings.
Figure 14 showcases a day from 2002 and 2006, emphasizing the different dynamical states of the GoM for these 2 years.
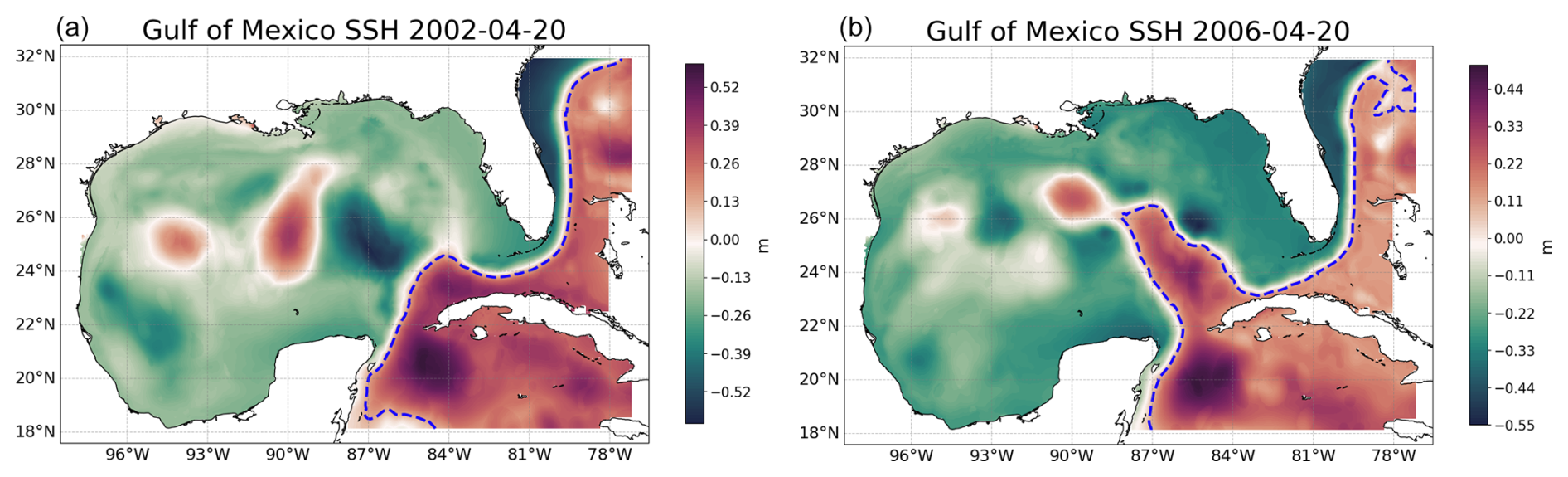
Figure 14Contrasting dynamical states of the Gulf of Mexico for years 2002 and 2006. Panel (a) illustrates the retracted loop current on 20 April 2002, while (b) depicts the extended loop current on 20 April 2006. Both cases are representative of the mean dynamical state of the GoM for that respective year.
The RMSE of the proposed model, trained with data from 2009 and 2010, is 4.39 mm for 2002 and 4.22 mm for 2006. This demonstrates how effectively the model is generalizing to new data and varying states of the GoM. It is anticipated that the model will yield similar results, with an RMSE around 4 mm, for any other time frame of the GoM. Figure 15 presents the RMSE obtained for every day in 2002 and 2006, along with the mean for the 2 years. The RMSE has increased from 3.7 mm in the test set to 4.2 mm in this new generalization test. This underscores the importance of identifying appropriate scenarios to test the generalization of our models. Specifically, in the context of ocean models, it is crucial to evaluate the model in different dynamical scenarios than the ones used for training the models to avoid overestimating metrics that may not hold up when using the model operationally.
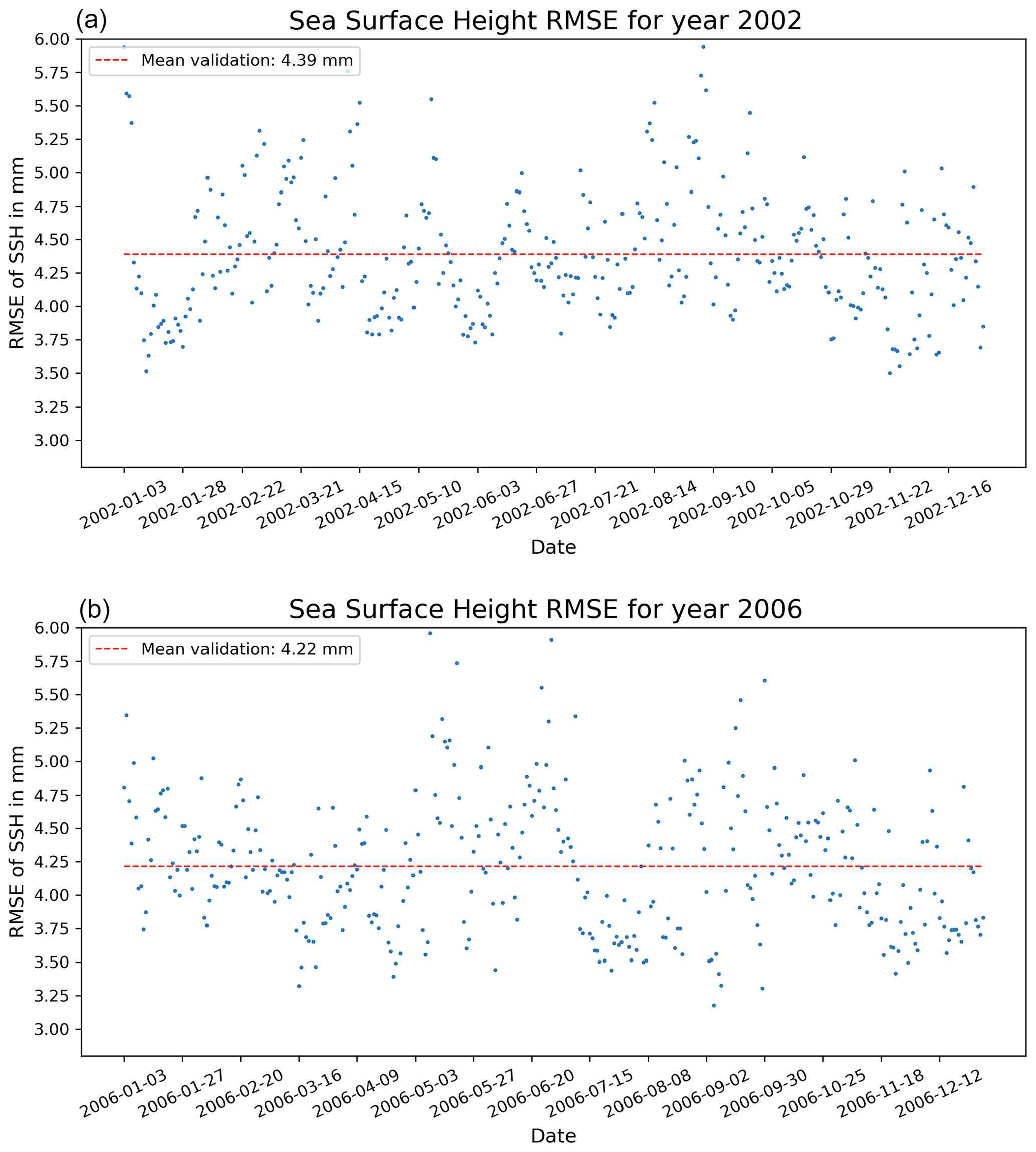
Figure 15Root mean square error (RMSE) of the proposed CNN model for the years 2002 (a) and 2006 (b). Vertical dashed lines represent the mean error across each respective year. Date format is year-month-day.
4.7 Performance comparison
The primary objective of this study is to explore the use of convolutional neural networks (CNNs) as a more efficient alternative to traditional data assimilation methods in oceanographic modeling. Comparing the performance between the proposed CNN model and the traditional T-SIS optimal interpolation method presents several challenges.
The proposed CNN model, still in the prototype stage, assimilates surface data for a single field at a time and, in some experiments, two fields. In contrast, the T-SIS data assimilation software is a fully operational package that simultaneously assimilates all HYCOM fields, including temperature, sea surface height, velocity fields U and V, and salinity, in the 41 vertical layers of the model. Furthermore, the T-SIS package is implemented in FORTRAN and is typically run on clusters of tens to hundreds of CPUs at high-performance computing (HPC) centers. Meanwhile, the proposed CNN model is implemented in TensorFlow with Python and utilizes GPUs, which may contain thousands of smaller processors.
In this performance analysis, we compare the times taken by T-SIS to assimilate a single day of observations under two different settings. The first setting involves execution on a cluster with 32 processors at the Florida State University HPC center and the second on the US Navy's Narwhal supercomputer with 96 processors. The proposed CNN model, assimilating a single surface field (1 d), takes 0.054±0.005 s on an NVIDIA Quadro RTX 4500 GPU.
To estimate performance in a full three-dimensional context (assimilating five fields across 41 vertical layers), we consider two scenarios. The first scenario, labeled CNN sequential, assumes no further parallelization, requiring multiplication of our observed times by both the number of fields and vertical levels (41×5). The second scenario, CNN parallel, assumes complete parallelization in three dimensions. The potential speedup of the proposed CNN model, compared to the 32-processor T-SIS, ranges from 1.9 to 389. Against the 96-processor T-SIS configuration, the speedup ranges from 0.73 (slower) to 150. The speedup or speedup factor is a unitless measure defined as the ratio of the time taken by the traditional T-SIS method to the time taken by our proposed CNN model for the same assimilation task. For example, a speedup factor of 58 indicates that the CNN model performs the assimilation 58 times faster than the T-SIS method running on a 32-processor cluster, while a speedup factor of 22 signifies a 22-fold increase in performance compared to the 96-processor T-SIS configuration.
Given the broad range of these results, we simulate the assimilation of all vertical layers by running our model in batches of 41, providing a more practical metric. In this scenario (CNN 41 batch), it takes 0.36±0.01 s to perform a single day's assimilation, resulting in more realistic expected speedups of 58 compared to the 32-processor T-SIS and 22 compared to the 96-processor T-SIS.
Table 3 displays the times, in seconds, taken by the T-SIS package to assimilate 1 d of data on an HPC cluster with 32 and 96 processors, along with estimates for times our model would require, assuming the ability to parallelize only the vertical layers as a batch and when full parallelization of the five fields is possible.
Table 3Comparison of simulation times for a single day of assimilated observations using T-SIS across various CPU configurations and the proposed CNN model with multiple estimated parallelization schemes. The bolded times and speedups highlight the most realistic comparison between our proposed AI implementation and the T-SIS package.

In this work, we conducted a series of experiments to analyze the performance of convolutional neural networks (CNNs) in emulating the data assimilation process within a realistic operational model setting. These experiments assessed various aspects of the CNNs, including architecture complexity, the types and quantities of observations (inputs), assimilated fields (outputs), responses to window size, and the influence of coastline on model performance.
The results demonstrated a clear relationship between the training window size and performance; larger window sizes generally result in better results, particularly when the full domain was used as the training window. Our experiments incorporating normalized latitude and longitude fields as inputs did not yield significant improvements in model performance. There was also a distinct correlation between the complexity of the CNN architecture and its performance, with deeper networks achieving superior outcomes and the U-net-based architectures outperformed other models. Our initial comparison between simple CNNs and the U-net architecture provided valuable insights into the importance of network complexity and the use of skip connections in capturing the spatial features necessary for accurate data assimilation emulation. Although simple CNNs are less commonly used in current geoscience applications, this analysis was important in demonstrating the necessity of employing advanced architectures like U-net for such complex tasks.
Our findings also indicated that even a shallow CNN with a simple architecture could assimilate SSH observations with an error margin of only 8 mm compared to the T-SIS assimilation package. Additionally, experiments assessing the impact of land on ocean models revealed that CNNs remained robust against land by simply zeroing out these regions, not affecting the models' performance based on the percentage of ocean used in the training data. Moreover, the experiments showcased the CNNs' ability to efficiently handle additional inputs without performance degradation and to assimilate multiple fields simultaneously. Another important aspect highlighted through our study is the importance of selecting appropriate test sets to evaluate the generalization capabilities of deep learning models, particularly when dealing with realistic ocean models over shorter timescales such as weeks or months. Using a random selection of training data as a test set could lead to misleadingly favorable results if the oceanographic conditions do not change significantly.
Data leakage is a critical issue in machine learning applications within Earth sciences due to the temporal and spatial dependencies in the data. Our approach of chronological data splitting and testing on entirely separate years aims to mitigate this concern. To test the generalization of our proposed model, we utilized data from 2 different years that presented varied dynamical states of the GoM. Although errors were slightly higher than with the initial test data (maybe due to the proximity of the training and test sets), an error of 4 mm was observed as a typical value when applying our CNN data assimilation (DA) method, and this is the expected error in our model in operational systems.
Furthermore, we compared the time performance of a traditional DA method (optimal interpolation), implemented in FORTRAN and executed on high-performance computing clusters, with our proposed CNN method running on a single GPU. These comparisons, while challenging, provided insights into potential time and cost savings achievable with new technologies. In our tests, the CNN model approximated the DA optimal interpolation method with less than a 4 mm error for SSH and achieved potential speedups of up to 58 times compared to systems running on a 32-processor cluster.
Despite ongoing research into explainable AI, which aims to better understand decisions made by deep learning models, these techniques typically do not analyze specific performance comparisons related to model design decisions. This work offers insights into the expected behavior of CNNs when applied to the specific problem of data assimilation in ocean models. Most findings from the proposed experiments should also be applicable in other scenarios where CNN models are used for “image-to-image” modeling in oceanic and atmospheric predictions involving geographic coordinates and diverse fields.
While our study focused on traditional CNN architectures, specifically U-nets, we acknowledge that newer deep learning techniques such as attention-based models (e.g., CBAM in SmaAt U-nets), vision transformers (ViTs), and denoising diffusion models have demonstrated superior performance in various image processing tasks by preserving fine details and reducing smoothing effects. Incorporating these advanced architectures into ocean data assimilation represents a promising direction for future research. However, due to computational constraints and the scope of this study, we did not explore these models. Future work will aim to investigate these techniques, leveraging their strengths to further enhance the accuracy and efficiency of data assimilation in ocean models.
The source code supporting the findings of this study is openly available in the “da_hycom” repository on GitHub, hosted at https://github.com/olmozavala/da_hycom (last access: 22 January 2025) or https://doi.org/10.5281/zenodo.14714803 (Zavala-Romero et al., 2025). The repository contains all necessary scripts required for implementing the models and algorithms discussed in this paper. Users can download, fork, or contribute to the project under the terms of the license specified within the repository.
The data used for training the models are available from the HYCOM (HYbrid Coordinate Ocean Model) website. Interested readers can access and download the training data by visiting the HYCOM project page at https://www.hycom.org/data/gomb0pt04/gom-reanalysis (Bozec et al., 2025). For any issues or further inquiries related to the code, please open an issue directly on the GitHub repository page.
OZR conceived and designed the experiments, ran all the machine learning training, analyzed the data, and wrote the majority of the paper. AB generated the data for training the models, configured the ocean model and the assimilation package, ran the assimilated HYCOM for all the years, and reviewed drafts of the paper. EPC conceived the general design of the research, analyzed the data, and reviewed drafts of the paper. JRM analyzed the data, wrote sections of the paper, and reviewed drafts of the paper.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This article is part of the special issue “Special Issue for the 54th International Liège Colloquium on Machine Learning and Data Analysis in Oceanography”. It is not associated with a conference.
We acknowledge the use of artificial intelligence tools which assisted in the editing of an earlier version of this paper.
This research has been supported by the Office of Naval Research (grant no. N00014-20-1-2023).
This paper was edited by Aida Alvera-Azcárate and reviewed by Michael Gray and one anonymous referee.
Agrawal, S., Barrington, L., Bromberg, C., Burge, J., Gazen, C., and Hickey, J.: Machine learning for precipitation nowcasting from radar images, arXiv [preprint], https://doi.org/10.48550/arXiv.1912.12132, 11 December 2019. a
Beauchamp, M., Bocquet, M., and Fablet, R.: Multimodal 4DVarNets for the reconstruction of sea surface dynamics from SST-SSH synergies, arXiv [preprint], https://doi.org/10.48550/arXiv.2203.06003, 11 March 2022. a
Bleck, R.: An oceanic general circulation model framed in hybrid isopycnic-Cartesian coordinates, Ocean Model., 4, 55–88, 2002. a, b
Boukabara, S.-A., Krasnopolsky, V., Stewart, J. Q., Maddy, E. S., Shahroudi, N., and Hoffman, R. N.: Leveraging modern artificial intelligence for remote sensing and NWP: Benefits and challenges, B. Am. Meteor. Soc., 100, ES473–ES491, 2019. a
Bozec, A., Chassignet, E. P., and Srinivasan, A.: GOMb0.04 Reanalysis for the Gulf of Mexico, https://www.hycom.org/data/gomb0pt04/gom-reanalysis (last access: 21 January 2025), 2025. a
Chassignet, E. P., Smith, L. T., Halliwell, G. R., and Bleck, R.: North Atlantic simulations with the Hybrid Coordinate Ocean Model (HYCOM): Impact of the vertical coordinate choice, reference pressure, and thermobaricity, J. Phys. Oceanogr., 33, 2504–2526, 2003. a, b
Chassignet, E. P., Hurlburt, H. E., Smedstad, O. M., Halliwell, G. R., Hogan, P. J., Wallcraft, A. J., Baraille, R., and Bleck, R.: The HYCOM (hybrid coordinate ocean model) data assimilative system, J. Mar. Syst., 65, 60–83, 2007. a
Chassignet, E. P., Hurlburt, H. E., Metzger, E. J., Smedstad, O. M., Cummings, J. A., Halliwell, G. R., Bleck, R., Baraille, R., Wallcraft, A. J., Lozano, C., et al.: US GODAE: global ocean prediction with the HYbrid Coordinate Ocean Model (HYCOM), Oceanography, 22, 64–75, 2009. a
Chin, T. M., Mariano, A. J., and Chassignet, E. P.: Spatial regression and multiscale approximations for sequential data assimilation in ocean models, J. Geophys. Res.-Oceans, 104, 7991–8014, 1999. a, b
Cooper, M. and Haines, K.: Altimetric assimilation with water property conservation, J. Geophys. Res.-Oceans, 101, 1059–1077, 1996. a
Daudt, R. C., Le Saux, B., Boulch, A., and Gousseau, Y.: Fully Convolutional Siamese Networks for Change Detection, in: IEEE International Conference on Image Processing (ICIP), Athens, Greece, 6 September 2018, 4063–4067, https://doi.org/10.1109/ICIP.2018.8451652, 2018. a
Davis, M.: Stochastic modelling and control, Springer Science & Business Media, https://doi.org/10.1007/978-94-009-4828-0, 2013. a
Demir, I., Koperski, K., Lindenbaum, D., Pang, G., Huang, J., Basu, S., Hughes, F., Tuia, D., and Raskar, R.: DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images, in: CVPR Workshops, Salt Lake City, June 2018, 172–181, 2018. a
Dong, R., Leng, H., Zhao, J., Song, J., and Liang, S.: A Framework for Four-Dimensional Variational Data Assimilation Based on Machine Learning, Entropy, 24, 264, https://doi.org/10.3390/e24020264, 2022. a
Evensen, G.: The ensemble Kalman filter: Theoretical formulation and practical implementation, Ocean Dynam., 53, 343–367, 2003. a
Geer, A. J.: Learning Earth System Models from Observations: Machine Learning or Data Assimilation?, Philos. T. Roy. Soc. A, 379, 20200089, https://doi.org/10.1098/rsta.2020.0089, 2021. a
Guinehut, S., Le Traon, P. Y., Larnicol, G., and Philipps, S.: Combining Argo and remote-sensing data to estimate the ocean three-dimensional temperature fields–a first approach based on simulated observations, J. Mar. Syst., 46, 85–98, https://doi.org/10.1016/j.jmarsys.2003.11.022, 2004. a
Kingma, D. P. and Ba, J.: Adam: A method for stochastic optimization, arXiv [preprint], https://doi.org/10.48550/arXiv.1412.6980, 22 December 2014. a
Krasnopolsky, V.: The Application of Neural Networks in the Earth System Sciences: Neural Network Emulations for Complex Multidimensional Mappings, vol. 46 of Atmospheric and Oceanic Science Library, Springer, Dordrecht, Heidelberg, New York, London, https://doi.org/10.1007/978-94-007-6073-8, 2013. a
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P.: Gradient-based learning applied to document recognition, P. IEEE, 86, 2278–2324, 1998. a
Lguensat, R., Sun, M., Fablet, R., Tandeo, P., Mason, E., and Chen, G.: EddyNet: A Deep Neural Network For Pixel-Wise Classification of Oceanic Eddies, in: IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, November 2018, 1764–1767, https://doi.org/10.1109/IGARSS.2018.8518411, 2018. a
Maggiori, E., Tarabalka, Y., Charpiat, G., and Alliez, P.: Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark, in: IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Forth Worth, TX, USA, 23–28 July 2017, 3226–3229, https://doi.org/10.1109/IGARSS.2017.8127684, 2017. a
Nicolas, K. M., Drumetz, L., Lefèvre, S., Tiede, D., Bajjouk, T., and Burnel, J.-C.: Deep Learning–Based Bathymetry Mapping from Multispectral Satellite Data Around Europa Island, in: European Spatial Data for Coastal and Marine Remote Sensing, edited by: Niculescu, S., Chapter 6, Springer, Cham, https://doi.org/10.1007/978-3-031-16213-8_6, 2023. a
Oke, P. R., Allen, J. S., Miller, R. N., Egbert, G. D., and Kosro, P. M.: Assimilation of surface velocity data into a primitive equation coastal ocean model, J. Geophys. Res.-Oceans, 107, 5-1–5-25, https://doi.org/10.1029/2000JC000511, 2002. a
Oktay, O., Schlemper, J., Folgoc, L. L., Lee, M., Heinrich, M., Misawa, K., Mori, K., McDonagh, S., Hammerla, N. Y., Kainz, B., Glocker, B., and Rueckert, D.: Attention u-net: Learning where to look for the pancreas, arXiv [preprint], https://doi.org/10.48550/arXiv.1804.03999, 11 April 2018. a
O'Shea, K. and Nash, R.: An Introduction to Convolutional Neural Networks, ar5iv.org, https://ar5iv.org/html/1511.08458 (last access: 1 June 2024), 2015. a, b
Panagiotis, V.: Gulf of Mexico high-resolution (0.01°× 0.01°) bathymetric grid-version 2.0, February 2013, Distributed by: Gulf of Mexico Research Initiative Information and Data Cooperative (GRIIDC), Harte Research Institute, Texas A&M UniversityCorpus Christi, https://doi.org/10.7266/N7X63JZ5, 2014. a
Pech-May, F., Aquino-Santos, R., Álvarez Cárdenas, O., Arandia, J. L., and Rios-Toledo, G.: Segmentation and Visualization of Flooded Areas Through Sentinel-1 Images and U-Net, IEEE J. Sel. Top. Appl., 17, 8996–9008, https://doi.org/10.1109/JSTARS.2024.3387452, 2024. a
Ronneberger, O., Fischer, P., and Brox, T.: U-net: Convolutional networks for biomedical image segmentation, in: International Conference on Medical image computing and computer-assisted intervention, 234–241, Springer, https://doi.org/10.1007/978-3-319-24574-4_28, 2015. a, b, c
Roy, A. G., Navab, N., and Wachinger, C.: Concurrent spatial and channel “squeeze & excitation” in fully convolutional networks, in: Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, 16–20 September 2018, Proceedings, Part I, 421–429, Springer, https://doi.org/10.1007/978-3-030-00928-1_48, 2018. a
Rue, H. and Held, L.: Gaussian Markov random fields: theory and applications, Chapman and Hall/CRC, https://doi.org/10.1201/9780203492024, 2005. a
Russwurm, M. and Korner, M.: Multi-temporal land cover classification with sequential recurrent encoders, ISPRS Int. J. Geo-Inf., 7, 129, 2018. a
Srinivasan, A., Chin, T., Chassignet, E., Iskandarani, M., and Groves, N.: A statistical interpolation code for ocean analysis and forecasting, J. Atmos. Ocean. Tech., 39, 367–386, 2022. a, b, c
Tian, S., Dong, Y., Feng, R., Liang, D., and Wang, L.: Mapping mountain glaciers using an improved U-Net model with cSE, Int. J. Digit. Earth, 15, 463–477, https://doi.org/10.1080/17538947.2022.2036834, 2022. a
Zavala-Romero, O., Bozec, A., Chassignet, E. P., and Miranda, J. R.: CNN-based data assimilation for operational ocean models (Gulf of Mexico case study), Version 1.0, Zenodo [software], https://doi.org/10.5281/zenodo.14714803, 2025. a
- Abstract
- Introduction
- The HYbrid Coordinate Ocean Model (HYCOM)
- Data assimilation with convolutional neural networks
- Results
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- The HYbrid Coordinate Ocean Model (HYCOM)
- Data assimilation with convolutional neural networks
- Results
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References